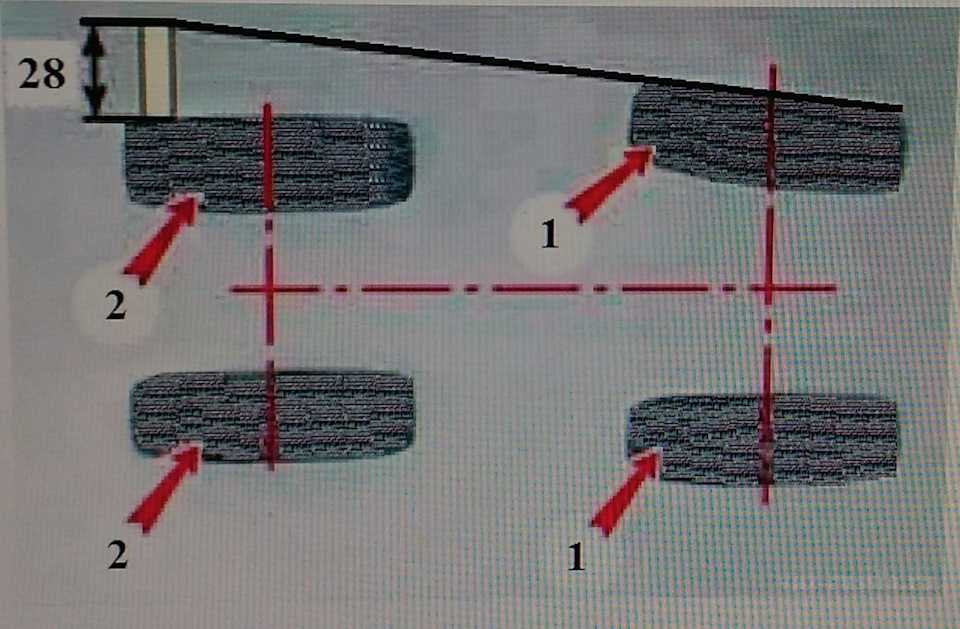
Развал схождение своими руками ВАЗ 2110
Угол кастера на ваз 2110 своими руками.
Как сделать развал-схождение своими руками.
Регулировка угла схождения колес.
Развал — схождение.
Развал схождение своими руками на нексии » Информация об автомобилях.
развал4.
Как отрегулировать развал схождение на ваз 2109.
Я выставлял отклонение 1,5-2 мм отвеса от кронштейна (могу ошибаться, надо .
Развал-схождение своими руками.
Диагностика и регулировка развала-схождения на Вольво.
Схождение колес автомобиля.
Геометрия передних колёс своими руками на примере ваз 2110.
Регулировка угла развала колес Ваз-2107.
Сход-развал своими руками.
регулировка угла развала и схождения.
Диагностика и регулировка развал-схождения колес в Твери- Колесо. 69.
69.
Развал схождение Ваз-2110.
Замена передних амортизаторов в машине Ваз 2110.
Ваз…
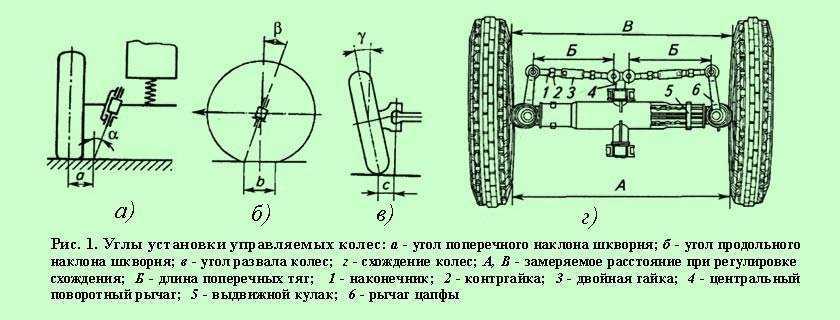
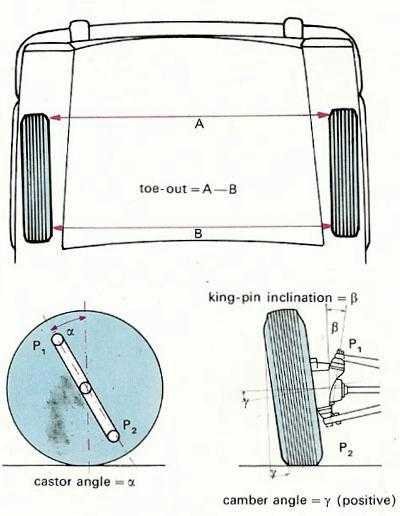
Углы установки передних колес
BMW E38 Club — Развал передних колес!
Lada 2109 Светло-серебристый.
Пошаговая инструкция — как заменить передний опорный подшипник ВАЗ 2110.
Развал-схождение.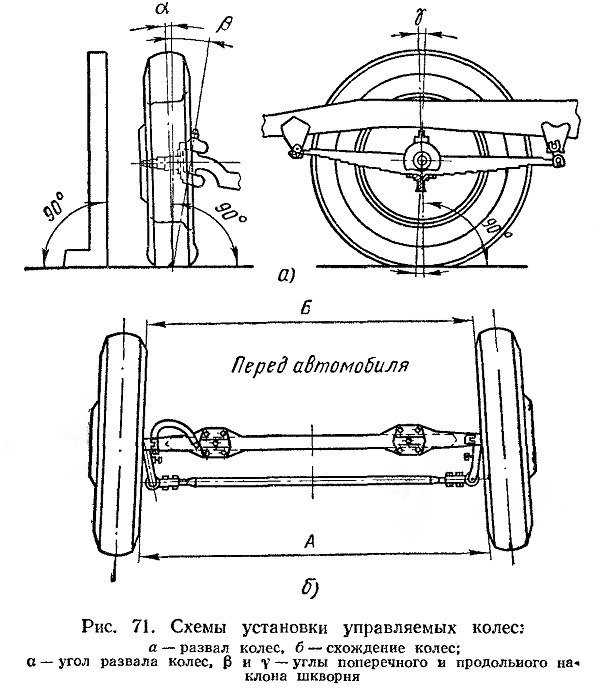
Углы передней подвески ЛАДА(ВАЗ) 2110, 2111, 2112.
Подвесной подшипник ваз 2106.
Ваз…
Регулировка схождения колес.Как отрегулировать схождение колес.
Впрочем, развал схождение своими руками ВАЗ 2110 вполне обычная процедура
Как проверить помпу на ваз 2110.
Развал схождение Своими руками, АНТИКРИЗИС.
 ВАЗ, лада калина, приора, гранта
ВАЗ, лада калина, приора, грантасодержание видео
Рейтинг: 4.0; Голоса: 1
Развал схождение Своими руками, АНТИКРИЗИС. ВАЗ, лада калина, приора, гранта Lelik Перепелицын: Я сам занимаюсь развалом уже 10 лет. Думаю я не самый плохой мастер. Почитал немного комментарии. Умников и диванных экспертов хватает. Способ показали неплохой Но он годится только для того чтобы доехать до нормального развала В моей практике встречались случаи, когда прибшизительная регулировка оказалась идеальной, но это не профессионализм а случайность. В общем цена на развал, в любом случае меньше чем пара колес. Есть народная мудрость Скупой платит дважды А тупой трижды.
Дата: 2019-06-26
← Какое масло залить в двигатель? трение 5 полусинтетика (10w 40)
Какое масло лучше залить в двигатель, ТРЕНИЕ 6 (10w 40) →
Похожие видео
Москвич 3 — Разобрали! Не пальцем сделано: )
• Клубный сервис
Шпатлевание под толщиномер, китайской металической шпатлёвкой.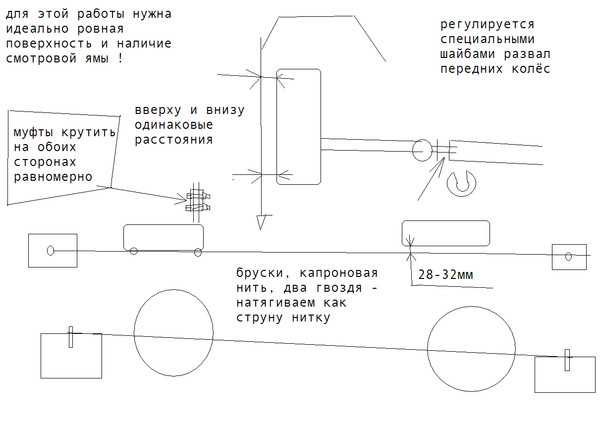
• Антон Маляр
Очень интересный случай! Kia ceed с сюрпризом!
• Максим Шелков — автоподбор
Свежий, бодрый и довольно надёжный Porsche Cayenne 3 поколения Подержанные автомобили
• Авто Плюс
Илюха собирает вещи и уходит(крутой подарок от подписчиков установка сигнала
• Большегруз 40rus
Новый кроссовер. Официально в рф самые дешевые 7 мест
• Лиса Рулит
Комментарии и отзывы: 7
GIG & bit
Я лично когда мой стенд выходил из строя делал настройки углов с уровнем и метром и так не замарачивался очень легко и просто только как говорится здесь в коментах нужно основание под ноль градус уровень нужен для развала а метр для схождения руль просто ставишь по центру в основном при стопорения руля он как выедешь всёравно не стоит идеально подкручивать приходится на это влияет несколько факторов но всёравно по сравнению со спец оборудованием это всё примерная настройка для того что бы не ела резину автор говорит правильно что развал схождения действую на те или иные характеристики но добиться идеальных настроек для того что бы они соттветствовали к большей ответственности перед требованием подвески при больших скоростях с полным экипажем на серпантинах в низ или на частых поворотах при не ровной дороге то нужен стенд отколеброванный однозначо потому что современная подвеска зделана так что бы все узлы сообша плавно изменяли своё положения относительно к крену кузова и при прохождения при не ровностях на дороге Удачи
Roman Demigov
Перед Устоновкой Сход-Розвала 1нужно подготовить Авто проверить при лювтах пробоях отремонтировать ходовую и сделать ревизию экцентриков. 2обротить внимание на износ шин и довления отбалансировать. После сильных ударов и после дтп проверить меж осное и по диогонали с ямы или на подемники росотояние геометрии кузова и подвески. 3 При устоновке Сход-Розвала на ровной площадке снять напрежение с ходовой чтоб колеса скользили и легкостью от поверхности поворачиваясь до упора под задние колеса поставить башмаки противо-отката и на ручник. Проверить Клиренс-дорожный просвет. Выкрутить руль до упора в прово и в лево поставить ровно в напровление двежения. Проверить наклон разворот колес по Сход-развалу Поперечному и Продольному и по мануалу по марке и класс машины в пределах допуска отрегулировать Сход-Розвал. На правой и левой стороне Угол наклона и разворота должен быть равный.
2обротить внимание на износ шин и довления отбалансировать. После сильных ударов и после дтп проверить меж осное и по диогонали с ямы или на подемники росотояние геометрии кузова и подвески. 3 При устоновке Сход-Розвала на ровной площадке снять напрежение с ходовой чтоб колеса скользили и легкостью от поверхности поворачиваясь до упора под задние колеса поставить башмаки противо-отката и на ручник. Проверить Клиренс-дорожный просвет. Выкрутить руль до упора в прово и в лево поставить ровно в напровление двежения. Проверить наклон разворот колес по Сход-развалу Поперечному и Продольному и по мануалу по марке и класс машины в пределах допуска отрегулировать Сход-Розвал. На правой и левой стороне Угол наклона и разворота должен быть равный.
Григорий Ивин
Давно пользуюсь таким методом. использую самую тонкую рыболовную леску, грузики и штангенциркуль. для схождения есть две рейки чуть шире машины на них одинаковые пропилы на одинаковом расстоянии. чтоб можно было натянуть точно параллельно друг другу лески. образуется рамка вокруг машины на высоте оси колес. дальше замеры, вычисления, регулировка. точность получается до 0. 1 градуса или 6 мин. точность достаточная, но не быстро, важно мерить по дискам, а не по резине. Для развала та же леска, грузики магниты на крылья для крепления лески, леска располагается перпендикулярно-вертикально осям колес, далее замеры вычисления регулировка. если по простому, по быстрому, то можно выставить все углы в ноль, т. е. обода дисков параллельно лескам.
образуется рамка вокруг машины на высоте оси колес. дальше замеры, вычисления, регулировка. точность получается до 0. 1 градуса или 6 мин. точность достаточная, но не быстро, важно мерить по дискам, а не по резине. Для развала та же леска, грузики магниты на крылья для крепления лески, леска располагается перпендикулярно-вертикально осям колес, далее замеры вычисления регулировка. если по простому, по быстрому, то можно выставить все углы в ноль, т. е. обода дисков параллельно лескам.
Владислав Назаренко
Хрен с ним с развалом, если у тебя идеально ровные полы (в уровень, то может быть такая метода имеет право на существование, а вот со схождением ты не прав, колейная разница передних и задних колёс на всех машинах разная, так что придётся ещё и проставочки заколхозить, прежде чем выводить нить в параллель с колесом, а так же надо учитывать какой привод у машины. Если задний то нужно схождение сделать чуть заваленным внутрь, ибо когда машина с задним приводом, передние колеса стремятся к расхождения на ружу. Соответственно если с передним приводом, то схождение вываливаем чуть на ружу.
Соответственно если с передним приводом, то схождение вываливаем чуть на ружу.
Driver 59
Очень сомнительная метода, я работал на техно вектор 6, калибровку производили раз в месяц, и периодически сталкивались с последствиями таких регулировок. люди не берут в расчет неровности пола, колеса просто могут быть завалены на пару градусов в одну сторону, причем это видно на подъемнике, но шнурок у них в гараже показывал уровень. Так же, пытаются регулировать с убитыми наглухо шинами и дисками. Ну и наконец, если даже угадать углы схождения и развала колес, но при этом кастер будет отличаться, все равно машину тянет в сторону.
Жан Жан
Я брал два правила по 3 метра которыми раствор выравнивают под маяк в строительстве, с помощью проволоки прикручивал к колесам чуть ниже оси и параллельно земле (важно чтобы под кузовом их визуально одновременно видно было) строго посередине. После чего с помощью обычной рулетки выставлял. Способ не работает если кривой развал и кривые диски и резина. Относительно задних колес тоже легко регулируется при условии что задняя подвеска относительно кузова вбок не съехавшая.
Относительно задних колес тоже легко регулируется при условии что задняя подвеска относительно кузова вбок не съехавшая.
Aleksey Romanov
Может я чего то не понимаю то поправте меня. Об разности колеи и ровности пола же упомянули. Но насколько я знаю колеса не стоят точно в горизонте и по схождению они тоже стоят не паралельно кузову. Так как при переднем приводе передок колес стремится сойтись так же и с задним только на оборот при этом развальщик должен учитывать эту погрешность и выставлять нужные углы что бы когда начнут действовать эти силы то колеса выровняются строго паралельно движению
GAN — Способы повышения производительности GAN | by Jonathan Hui
Фото Andy BealesМодели GAN могут сильно пострадать в следующих областях по сравнению с другими глубокими сетями.
- Несходимость : модели не сходятся и, что еще хуже, становятся нестабильными.
- Сбой режима : генератор выдает ограниченные режимы, и
- Медленное обучение: исчез градиент для обучения генератора.


В этой статье, посвященной GAN, рассматриваются способы улучшения GAN. В частности,
- Измените функцию стоимости для лучшей цели оптимизации.
- Добавьте дополнительные штрафы к функции стоимости для обеспечения соблюдения ограничений.
- Избегайте самоуверенности и переобучения.
- Улучшенные способы оптимизации модели.
- Добавить метки.
Но имейте в виду, что это динамичная тема, так как исследования продолжаются очень активно.
Генератор пытается найти лучшее изображение, чтобы обмануть дискриминатор. «Лучший» образ продолжает меняться, когда обе сети противодействуют своему противнику. Однако оптимизация может оказаться слишком жадной и превратить ее в бесконечную игру в кошки-мышки. Это один из сценариев, когда модель не сходится и мода рушится.
Сопоставление признаков изменяет функцию стоимости для генератора, минимизируя статистическую разницу между признаками реальных изображений и сгенерированных изображений. Часто мы измеряем L2-расстояние между средними значениями их векторов признаков. Таким образом, сопоставление признаков расширяет цель от победы над противником до сопоставления признаков на реальных изображениях. Вот новая целевая функция:
Часто мы измеряем L2-расстояние между средними значениями их векторов признаков. Таким образом, сопоставление признаков расширяет цель от победы над противником до сопоставления признаков на реальных изображениях. Вот новая целевая функция:
, где f(x) — это вектор признаков, извлеченный в непосредственном слое дискриминатором.
Средние значения характеристик реального изображения вычисляются для каждой мини-партии, которые колеблются в каждой партии. Это хорошая новость в смягчении коллапса режима. Это вводит случайность, из-за которой дискриминатору труднее переобучить себя.
Сопоставление функций эффективно, когда модель GAN нестабильна во время обучения.
При сворачивании режима все созданные изображения выглядят одинаково. Чтобы смягчить проблему, мы загружаем в дискриминатор реальные изображения и сгенерированные изображения отдельно в разных пакетах и вычисляем сходство изображения x с изображениями в одном пакете. Мы добавляем сходство o(x) в один из плотных слоев дискриминатора, чтобы классифицировать, является ли это изображение реальным или сгенерированным.
Мы добавляем сходство o(x) в один из плотных слоев дискриминатора, чтобы классифицировать, является ли это изображение реальным или сгенерированным.
Если мод начинает схлопываться, сходство сгенерированных изображений увеличивается. Дискриминатор может использовать эту оценку для обнаружения сгенерированных изображений и наказания генератора, если режим рушится.
Сходство o(xi) между изображением xi и другие изображения в том же пакете вычисляются с помощью матрицы преобразования T . Уравнения немного сложно отследить, но концепция довольно проста. Но не стесняйтесь переходить к следующему разделу, если хотите.
На рисунке выше xi — входное изображение, а xj — остальные изображения в том же пакете. Мы используем матрицу преобразования T для преобразования функций 9от 0040 xi до Mi , который представляет собой матрицу B×C.
Мы получаем сходство c(xi, xj) между изображением i и j , используя L1-норму и следующее уравнение.
Сходство o(xi) между изображением xi и остальными изображениями в пакете составляет
Методы обучения GAN»
Дискриминация в мини-пакетах позволяет нам очень быстро создавать визуально привлекательные образцы, и в этом отношении она превосходит сопоставление признаков.
Глубинные сети могут страдать от самоуверенности. Например, он использует очень мало признаков для классификации объекта. Чтобы смягчить проблему, глубокое обучение использует регулирование и отсев, чтобы избежать чрезмерной уверенности.
В GAN, если дискриминатор зависит от небольшого набора функций для обнаружения реальных изображений, генератор может просто создавать эти функции только для использования дискриминатора. Оптимизация может оказаться слишком жадной и не даст долгосрочной выгоды. В GAN излишняя самоуверенность очень вредит. Чтобы избежать этой проблемы, мы штрафуем дискриминатор, когда предсказание для любых реальных изображений превышает 0,9.( D (реальное изображение) > 0,9 ). Это делается путем установки нашего целевого значения метки равным 0,9 вместо 1,0. Вот псевдокод:
Оптимизация может оказаться слишком жадной и не даст долгосрочной выгоды. В GAN излишняя самоуверенность очень вредит. Чтобы избежать этой проблемы, мы штрафуем дискриминатор, когда предсказание для любых реальных изображений превышает 0,9.( D (реальное изображение) > 0,9 ). Это делается путем установки нашего целевого значения метки равным 0,9 вместо 1,0. Вот псевдокод:
p = tf.placeholder(tf.float32, shape=[None, 10])# Используйте 0,9 вместо 1,0.
feed_dict = {
p: [[0, 0, 0, 0.9, 0, 0, 0, 0, 0, 0]] # Изображение с меткой "3"
}# logits_real_image - это логиты, вычисленные
# дискриминатором для реальных изображений.
d_real_loss = tf.nn.sigmoid_cross_entropy_with_logits(
labels=p, logits=logits_real_image)
При историческом усреднении мы отслеживаем параметры модели для последних моделей t . В качестве альтернативы мы обновляем скользящее среднее параметров модели, если нам нужно сохранить длинную последовательность моделей.
Мы добавляем приведенную ниже стоимость L2 к функции стоимости, чтобы оштрафовать модель, отличающуюся от среднего исторического значения.
Для GAN с невыпуклой функцией объекта историческое усреднение может остановить модели, вращающиеся вокруг точки равновесия, и действовать как демпфирующая сила для сходимости модели.
Оптимизация модели может быть слишком жадной для подавления того, что в данный момент генерирует генератор. Чтобы решить эту проблему, воспроизведение опыта поддерживает самые последние сгенерированные изображения из прошлых итераций оптимизации. Вместо подбора моделей только текущими сгенерированными изображениями мы также подаем на дискриминатор все последние сгенерированные изображения. Следовательно, дискриминатор не будет переобучен для конкретного временного экземпляра генератора.
Многие наборы данных снабжены метками для типов объектов их выборок. Тренировать ГАН уже тяжело. Таким образом, любая дополнительная помощь в обучении GAN может значительно улучшить производительность.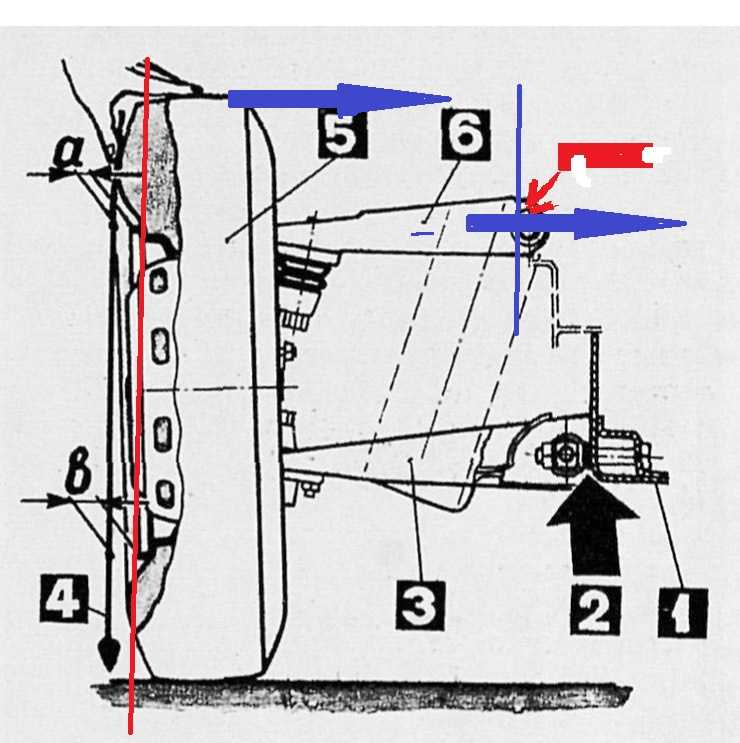 Добавление метки как части скрытого пространства z помогает обучению GAN. Ниже показан поток данных, используемый в CGAN для использования меток в образцах.
Добавление метки как части скрытого пространства z помогает обучению GAN. Ниже показан поток данных, используемый в CGAN для использования меток в образцах.
Имеют ли значение функции затрат? Так и должно быть, иначе все эти исследовательские усилия окажутся напрасными. Но если вы услышите о статье Google Brain за 2017 год, у вас обязательно возникнут сомнения. Но повышение качества изображения по-прежнему остается главным приоритетом. Скорее всего, мы увидим, как исследователи пробуют разные функции затрат, прежде чем мы получим точный ответ на вопрос о достоинствах.
На следующем рисунке перечислены функции стоимости для некоторых распространенных моделей GAN.
Таблица изменена отсюда. Мы решили не детализировать эти функции стоимости в этой статье. Вот статьи, в которых подробно рассматриваются некоторые общие функции затрат: WGAN/WGAN-GP, EBGAN/BEGAN, LSGAN, RGAN и RaGAN. В конце этой статьи мы перечисляем статью, в которой все эти функции стоимости изучаются более подробно.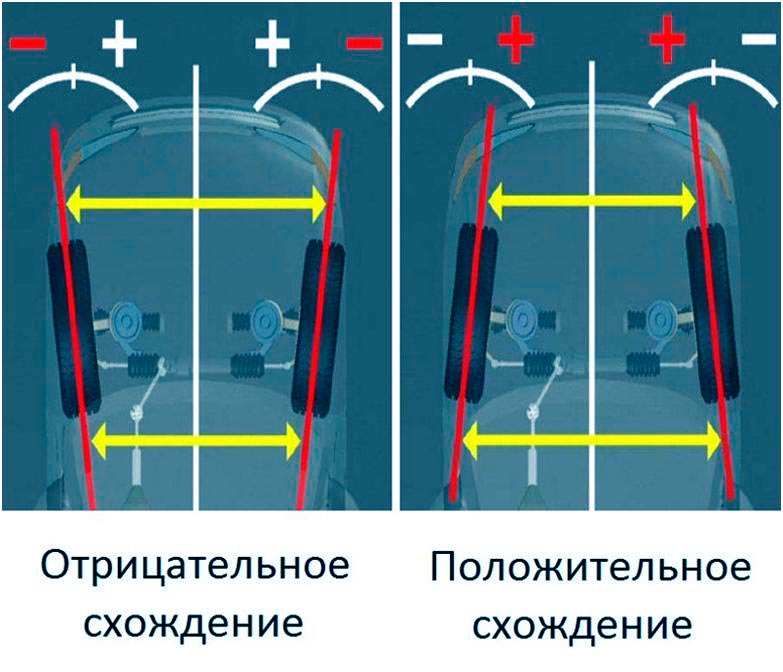 Поскольку функция стоимости является одной из основных областей исследований в GAN, мы рекомендуем вам прочитать эту статью позже.
Поскольку функция стоимости является одной из основных областей исследований в GAN, мы рекомендуем вам прочитать эту статью позже.
Вот некоторые оценки FID (чем ниже, тем лучше) для некоторых наборов данных. Это один ориентир, но имейте в виду, что еще слишком рано делать какие-либо выводы о том, какие функции затрат работают лучше всего. Действительно, пока не существует единой функции стоимости, которая бы работала лучше всего среди всех различных наборов данных.
Источник(MM GAN — это функция стоимости GAN в оригинальной статье. NS GAN — это альтернативные функции стоимости, учитывающие исчезающие градиенты в той же статье.)
Но ни одна модель не работает хорошо без хороших гиперпараметров, а настройка GAN требует времени. Будьте терпеливы в оптимизации гиперпараметров, прежде чем случайным образом тестировать различные функции стоимости. Некоторые исследователи предположили, что настройка гиперпараметров может принести большую отдачу, чем изменение функций затрат.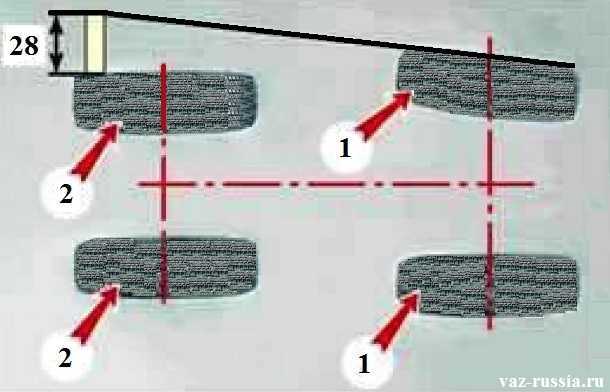 Тщательно настроенная скорость обучения может смягчить некоторые серьезные проблемы GAN, такие как сбой режима. В частности, снизьте скорость обучения и повторите обучение, когда произойдет сбой режима.
Тщательно настроенная скорость обучения может смягчить некоторые серьезные проблемы GAN, такие как сбой режима. В частности, снизьте скорость обучения и повторите обучение, когда произойдет сбой режима.
Мы также можем поэкспериментировать с разными скоростями обучения для генератора и дискриминатора. Например, на следующем графике используется скорость обучения 0,0003 для дискриминатора и 0,0001 для генератора в обучении WGAN-GP.
Источник- Масштабируйте значение пикселя изображения от -1 до 1. Используйте tanh в качестве выходного слоя для генератора.
- Экспериментальная выборка z с распределением Гаусса.
- Пакетная нормализация часто стабилизирует обучение.
- Использовать PixelShuffle и транспонировать свертки для повышения дискретизации.
- Избегайте максимального объединения для понижения частоты дискретизации. Используйте сверточный шаг.
- Оптимизатор Adam обычно работает лучше других методов.
- Добавьте шум к реальным и сгенерированным изображениям перед их подачей в дискриминатор.
Динамика моделей GAN еще недостаточно изучена. Таким образом, некоторые советы являются всего лишь предложениями, и пробег может варьироваться. Например, в документе LSGAN сообщается, что RMSProp имеет более стабильное обучение в своих экспериментах. Это довольно редкое явление, но оно демонстрирует трудности с составлением общих рекомендаций.
Дискриминатор и генератор постоянно конкурируют друг с другом. Будьте готовы к тому, что значение функции стоимости может увеличиваться и уменьшаться. Не прекращайте обучение преждевременно, даже если может показаться, что стоимость растет. Визуально контролируйте результаты, чтобы проверить ход обучения.
Пакетная нормализация BM становится стандартом де-факто во многих проектах глубоких сетей. Среднее значение и дисперсия BM получены из текущей мини-партии. Однако это создает зависимость между образцами. Сгенерированные изображения не являются независимыми друг от друга.
Это отражено в экспериментах, в которых сгенерированные изображения демонстрируют цветовой оттенок в одной и той же партии.
Оранжевый оттенок на верхней партии и зеленоватый оттенок на второй. ИсточникПервоначально мы выбираем z из случайного распределения, которое дает нам независимые выборки. Однако смещение, создаваемое пакетной нормализацией, подавляет случайность z .
Нормализация виртуальной партии (VBN) отбирает контрольную партию перед обучением. На прямом проходе мы можем предварительно выбрать эталонную партию для вычисления параметров нормализации ( μ и σ) для BN. Однако мы подгоним модель к этой эталонной партии, поскольку используем одну и ту же партию для всего обучения. Чтобы смягчить это, мы можем объединить эталонную партию с текущей партией для вычисления параметров нормализации.
Случайные начальные значения, используемые для инициализации параметров модели, влияют на производительность GAN. Как показано ниже, оценки FID при измерении производительности GAN различаются в 50 отдельных прогонах (обучение). Но диапазон относительно невелик и, вероятно, будет выполнен только в более поздней точной настройке.
Как показано ниже, оценки FID при измерении производительности GAN различаются в 50 отдельных прогонах (обучение). Но диапазон относительно невелик и, вероятно, будет выполнен только в более поздней точной настройке.
В документе Google Brain указано, что LSGAN иногда дает сбой или рушится в некоторых наборах данных, и обучение необходимо перезапустить с другим случайным начальным числом.
DGCAN настоятельно рекомендует добавить BM в проект сети. Использование BM также стало общей практикой во многих моделях глубоких сетей. Однако будут исключения. На следующем рисунке показано влияние BN на различные наборы данных. Ось y представляет собой оценку FID, которая чем ниже, тем лучше. Как указано в документе WGAN-GP, при использовании BN должен быть выключен. Мы предлагаем читателям проверить используемую функцию стоимости и соответствующую производительность FID на BN, а также проверить настройку с помощью экспериментов.
Изменено из исходного кода. Спектральная нормализация — это нормализация веса, которая стабилизирует обучение дискриминатора. Он управляет константой Липшица дискриминатора, чтобы смягчить проблему взрывающегося градиента и проблему коллапса моды. Концепция в значительной степени основана на математике, но концептуально она ограничивает изменения веса на каждой итерации, а не зависит от небольшого набора признаков при различении изображений дискриминатором. Этот подход будет легким в вычислительном отношении по сравнению с WGAN-GP и обеспечит хорошее покрытие режима, которое преследует многие методы GAN.
Он управляет константой Липшица дискриминатора, чтобы смягчить проблему взрывающегося градиента и проблему коллапса моды. Концепция в значительной степени основана на математике, но концептуально она ограничивает изменения веса на каждой итерации, а не зависит от небольшого набора признаков при различении изображений дискриминатором. Этот подход будет легким в вычислительном отношении по сравнению с WGAN-GP и обеспечит хорошее покрытие режима, которое преследует многие методы GAN.
Крах режима может быть не так уж и плох. Качество изображения часто улучшается, когда режим рушится. Фактически, мы можем собрать лучшую модель для каждого режима и использовать их для воссоздания различных режимов изображений.
Источник Дискриминатор и генератор всегда находятся в перетягивании каната, чтобы подорвать друг друга. Коллапс моды и уменьшение градиента часто объясняют дисбалансом между дискриминатором и генератором. Мы можем улучшить GAN, обратив внимание на балансировку потерь между генератором и дискриминатором. К сожалению, решение кажется неуловимым. Мы можем поддерживать статическое соотношение между количеством итераций градиентного спуска на дискриминаторе и генераторе. Даже это кажется привлекательным, но многие сомневаются в его пользе. Часто мы поддерживаем соотношение один к одному. Но некоторые исследователи также проверяют соотношение 5 итераций дискриминатора на одно обновление генератора. Также предлагается сбалансировать обе сети с помощью динамической механики. Но только в последние годы мы получили некоторую поддержку.
К сожалению, решение кажется неуловимым. Мы можем поддерживать статическое соотношение между количеством итераций градиентного спуска на дискриминаторе и генераторе. Даже это кажется привлекательным, но многие сомневаются в его пользе. Часто мы поддерживаем соотношение один к одному. Но некоторые исследователи также проверяют соотношение 5 итераций дискриминатора на одно обновление генератора. Также предлагается сбалансировать обе сети с помощью динамической механики. Но только в последние годы мы получили некоторую поддержку.
С другой стороны, некоторые исследователи оспаривают осуществимость и желательность балансировки этих сетей. Хорошо обученный дискриминатор в любом случае дает генератору качественную обратную связь. Кроме того, непросто научить генератор всегда догонять дискриминатор. Вместо этого мы можем обратить внимание на поиск функции стоимости, которая не имеет близкого к нулю градиента, когда генератор работает плохо.
Тем не менее, проблемы остаются. Внесено много предложений по функциям затрат, и споры о том, что лучше, продолжаются.
Модель дискриминатора обычно сложнее генератора (больше фильтров и слоев), и хороший дискриминатор дает качественную информацию. Во многих приложениях GAN мы можем столкнуться с узкими местами, где увеличение мощности генератора не приводит к улучшению качества. Пока мы не выявим узкие места и не устраним их, увеличение мощности генератора не кажется приоритетом для многих разделителей.
BigGAN был опубликован в 2018 году с целью объединить некоторые методы GAN для создания лучших изображений на тот момент. В этом разделе мы изучим некоторые еще не рассмотренные практики.
Больший размер партии
Источник (Чем меньше показатель FID, тем лучше) Увеличение размера партии может привести к значительному снижению FID, как показано выше. При большем размере пакета охвачено больше режимов, что обеспечивает лучшие градиенты для обучения обеих сетей. Но тем не менее, BigGAN сообщает, что модель достигает лучшей производительности за меньшее количество итераций, но впоследствии становится нестабильной и даже рушится. Итак, сохраняйте модель постоянно.
Итак, сохраняйте модель постоянно.
Трюк с усечением
Область низкой плотности вероятности в скрытом пространстве z может не хватить обучающих данных для точного обучения. Таким образом, при создании изображений мы можем избежать этих областей, чтобы улучшить качество изображения за счет изменения. то есть качество изображений повысится, но сгенерированные изображения будут иметь меньшую вариативность стиля. Существуют различные способы усечения входного скрытого пространства z . Общий принцип заключается в том, что когда значения выходят за пределы диапазона, они будут пересчитаны или сжаты до области с более высокой вероятностью.
Увеличить емкость модели
Во время настройки рассмотрите возможность увеличения емкости модели, особенно для слоев с высоким пространственным разрешением. Многие модели показывают улучшение, когда удваивают традиционную емкость, использовавшуюся в то время. Но не делайте этого слишком рано, не проверив дизайн модели и ее реализацию.
Скользящие средние весов генератора
Веса, используемые генератором, вычисляются из экспоненциального скользящего среднего весов генератора.
Ортогональная регуляризация
Состояние весовой матрицы является хорошо изученной темой. Это исследование того, насколько чувствителен вывод функции к изменениям ее ввода. Это оказывает большое влияние на стабильность тренировок. Матрица Q является ортогональной, если
Если мы умножим x на ортогональную матрицу, изменения в x не будут увеличены. Такое поведение очень желательно для поддержания численной стабильности.
С другими свойствами сохранение ортогональных свойств весовой матрицы может быть привлекательным в глубоком обучении. Мы можем добавить ортогональную регуляризацию, чтобы поощрять такие свойства во время обучения. Это наказывает систему, если Q отклоняется от ортогональной матрицы.
Тем не менее, известно, что это слишком ограничивает, и поэтому BigGAN использует измененный термин:
Ортогональная регуляризация также позволяет трюку с усечением быть более успешным в разных моделях.
Инициализация ортогонального веса
Вес модели инициализируется как случайная ортогональная матрица.
Соединение Skip-z
В ванильном GAN скрытый фактор z вводится только для первого слоя. С подключением skip-z, прямым подключением skip (skip-z) из латентного фактора z подключен к нескольким слоям генератора, а не только к первому слою.
В этой статье мы не будем подробно рассматривать улучшение с помощью функции затрат. Это важная тема, и мы рекомендуем читателям прочитать следующую статью:
GAN — всесторонний обзор гангстеров GAN (Часть 2)
В этой статье рассматриваются мотивация и направление исследований GAN по улучшению GAN. Просмотрев их на…
medium.com
Чтобы узнать больше о крутых приложениях GAN:
GAN — Несколько крутых приложений GAN.
Мы добились впечатляющих успехов в первые несколько лет разработки GAN. Больше никаких фотографий лица размером с марку, как эти…
medium.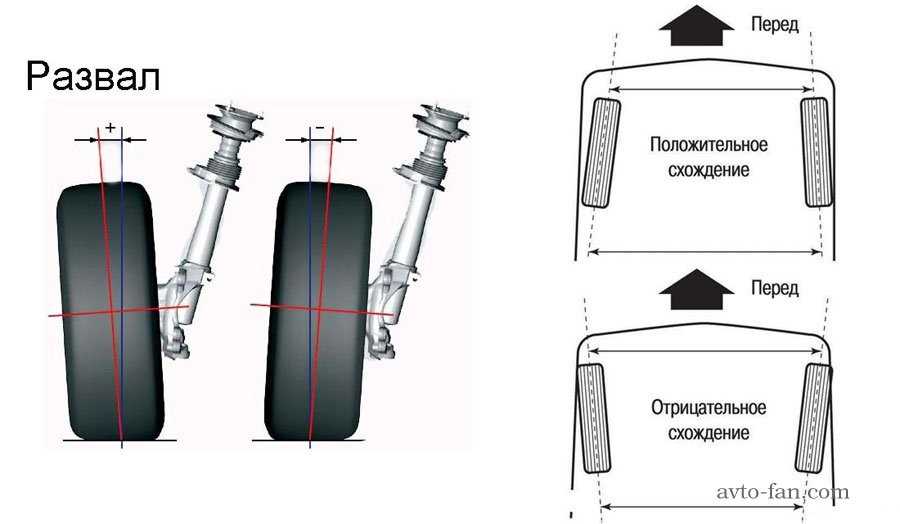 com
com
Все статьи этой серии.
GAN — Серия GAN (от начала до конца)
Полный список наших статей охватывает применение GAN, проблемы и решения.
medium.com
Улучшенные методы обучения GAN
Дивергентное и конвергентное мышление в процессе проектирования – статьи Мишель Оваль
Дизайнерское мышление поначалу может показаться немного нечетким. Как описывает это Идео: «Единого определения дизайн-мышления не существует. Это идея, стратегия, метод и способ видения мира». Нечеткий действительно. Это процесс и образ мышления. Это требует как эмпатического , так и аналитического мышления. Кроме того, мы должны переключаться между дивергентным и конвергентным мышлением!
Что такое дивергентное и конвергентное мышление?«Единого определения дизайн-мышления не существует. Это идея, стратегия, метод и способ видения мира».
Ideo
Дивергенция и конвергенция — взаимодополняющие способы мышления, каждый из которых имеет свое практическое применение и преимущества.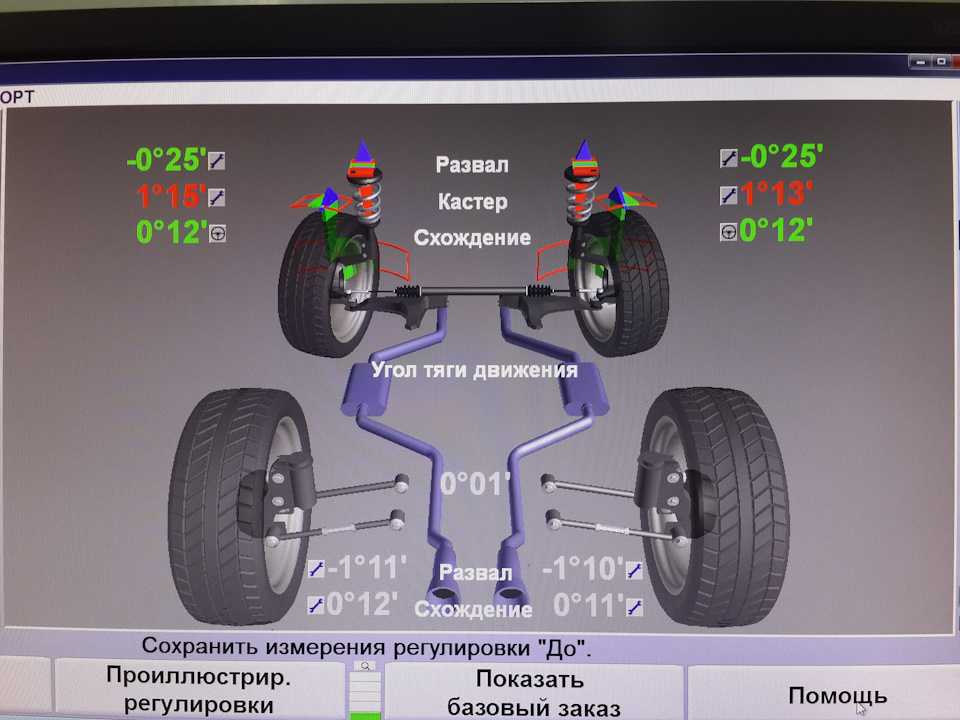 В дизайн-мышлении мы прыгаем между каждым из них на протяжении всего процесса.
В дизайн-мышлении мы прыгаем между каждым из них на протяжении всего процесса.
В качестве примера возьмем приготовление ужина. Вы только что вернулись с работы и проголодались… но вы также давно не были в продуктовом магазине, поэтому ваши запасы на исходе. Вы изучаете, с какими ингредиентами вам приходится работать. Мысленно вы представляете все возможные комбинации, чтобы приготовить вкусную еду. Ни одна идея не обсуждается, и вы наслаждаетесь процессом изобретения множества вариантов. Песто из цуккини… почему бы и нет?! В данный момент вы тренируетесь дивергентное мышление . При дивергентном мышлении ваш разум расширяется, когда вы генерируете как можно больше идей. Вместо того, чтобы жаловаться на отсутствие ингредиентов, необходимых для приготовления того или иного блюда, вы принимаете вызов создать что-то новое, используя то, что у вас есть. Как говорит Идео, в дивергенции вы «создаете выбор».
При дивергентном мышлении ваш разум расширяется, когда вы генерируете как можно больше идей.

Хорошо, вернемся к ужину. После того, как вы изучили все варианты питания, вы начинаете сужать свои варианты. Вы можете решить приготовить блюдо из определенного овоща, прежде чем оно испортится, или выбрать самый быстрый и простой вариант, который вы придумали — это конвергентное мышление . При конвергентном мышлении вы анализируете и синтезируете имеющуюся у вас информацию и используете ее для принятия обоснованных решений. Как описывает это Идео, при конвергенции вы «делаете выбор».
Изображение получено с https://designthinking.ideo.com/При конвергентном мышлении вы анализируете и синтезируете имеющуюся у вас информацию и используете ее для принятия обоснованных решений.
Дизайн-мышление — это естественный прилив и отлив между дивергентным и конвергентным мышлением. По мере прохождения каждого итеративного этапа наше мышление должно меняться вместе с нами.
Дивергенция на этапе Empathize В Empathize вы стремитесь понять своих пользователей и их текущие проблемы с конкретным продуктом, услугой или ситуацией. Вы внимательно наблюдаете за ними, общаетесь с ними лично, погружаетесь в их мир и пытаетесь увидеть вещи через их призму. Сохранение непредвзятости, отказ от суждений и изучение всех возможностей требуют дивергентного мышления.
Вы внимательно наблюдаете за ними, общаетесь с ними лично, погружаетесь в их мир и пытаетесь увидеть вещи через их призму. Сохранение непредвзятости, отказ от суждений и изучение всех возможностей требуют дивергентного мышления.
Дизайн взаимодействия с пользователем зависит от исследований. На этапе исследования вы проводите сочетание вторичных, первичных, количественных и качественных исследований, чтобы понять своих пользователей и контекст дизайна.
Заявления о потребностях и чувствах пользователейЭто небольшое упражнение напомнит вам, что ваши пользователи — настоящие люди с настоящими чувствами. Это позволит вам оставаться на связи с ними на протяжении всего процесса проектирования. Узнайте больше о заявлениях о потребностях/чувствах пользователей здесь.
Карты эмпатии Карты эмпатии описывают поведение, мотивацию и отношение пользователя. Это поможет вам и вашей команде сосредоточиться на создании продуктов для нужд пользователей, а не для ваших собственных желаний. Узнайте больше об элементах карты эмпатии здесь.
Это поможет вам и вашей команде сосредоточиться на создании продуктов для нужд пользователей, а не для ваших собственных желаний. Узнайте больше об элементах карты эмпатии здесь.
Чрезвычайно популярные в UX-дизайне персонажи используют рассказывание историй для передачи данных. Превращая абстрактные данные в истории о людях, персонажи вооружают дизайнерские команды сочувствием к своим пользователям. Узнайте, как создать персону здесь.
Карты путешествияКарта пути — это визуальная форма повествования, которая обеспечивает общее представление для заинтересованных сторон, которое показывает, как и где пользовательские сегменты взаимодействуют с их брендом, продуктом или услугой. Карта пути предназначена для выявления полезных идей и возможностей, которые компании могут использовать для разработки более эффективных стратегий с учетом интересов своих клиентов.
Здесь вы можете ознакомиться с моим личным исследованием составления карты путешествий и опыта бронирования путешествий.
После погружения в мир ваших пользователей на этапе сопереживания вы просматриваете все свои данные на этапе определения. Выявление ценной информации, выявление проблемы и ее четкое формулирование требуют конвергентного мышления.
Методы определения помогают синтезировать информацию и осмысливать ее. Постановка проблемы«Если бы у меня был час на решение проблемы, я бы потратил 55 минут на обдумывание проблемы и 5 минут на размышления о решениях».
Альберт Эйнштейн
Постановка проблемы идентифицирует пользователя, его проблему и причины, по которым он сталкивается с этой проблемой. Продуманные и хорошо продуманные формулировки проблем имеют решающее значение для успеха вашего продукта. Они обеспечивают четкую цель для вашей команды, чтобы решить и дать вашему проекту меру успеха. Узнайте, как составить четкую постановку задачи, здесь.
Заявления точки зрения (POV) — это один из конкретных типов постановки проблемы. Заявление POV — это возможность рассказать содержательную историю, в которой собрана ценная информация о пользователе, его потребностях и вашем понимании ситуации. Комментарии должны быть четкими и лаконичными, но при этом увлекательными. Узнайте об утверждении «Анатомия точки зрения» (POV) здесь.
Снова дивергенция в фазе создания идейВ фазе формирования идей мы возвращаемся к дивергентному мышлению, чтобы исследовать каждую возможную идею для решения нашей четко определенной проблемы или постановки точки зрения. Идите широко и смело с идеями — не ограничивайте творчество суждениями.
Идеи требуют высокого уровня дивергентного мышления, поскольку вы готовите новые идеи для решения поставленной задачи. Вопросы «Как мы могли бы» HMW обычно используются на этапе создания идей в процессе дизайн-мышления, чтобы стимулировать дивергентное мышление.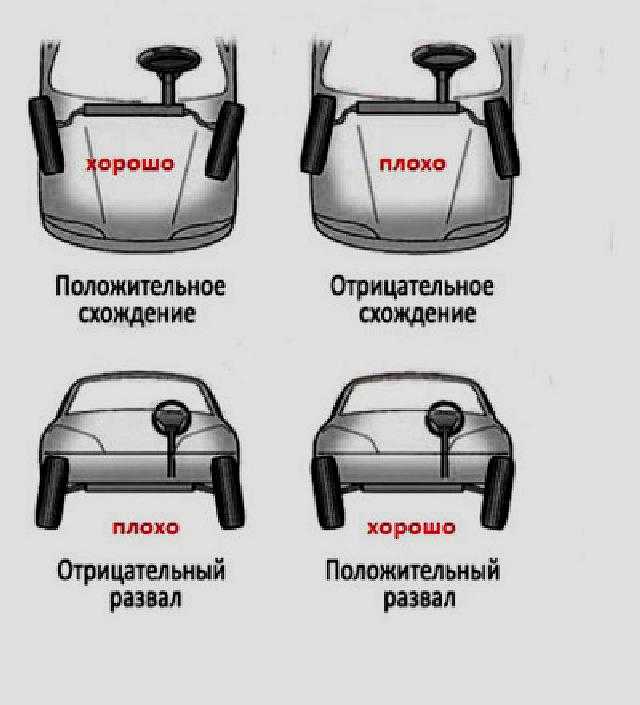 Как объяснили в стэнфордской школе d.school: «Цель (How Might We) состоит в том, чтобы создавать вопросы, которые вызывают значимые и актуальные идеи; делайте это, сохраняя проницательность и нюансы вопросов ».
Как объяснили в стэнфордской школе d.school: «Цель (How Might We) состоит в том, чтобы создавать вопросы, которые вызывают значимые и актуальные идеи; делайте это, сохраняя проницательность и нюансы вопросов ».
Цель (How Might We) состоит в том, чтобы создавать вопросы, которые вызывают значимые и актуальные идеи; сделать это, сохраняя вопросы проницательными и нюансами.
Standord d.school
Узнайте о ценности утверждений How Might We в процессе формирования идей здесь.
Методы генерирования идейВ процессе генерирования идей вы и ваша команда проводите мозговой штурм различных решений вашей проблемы. Есть много методов, используемых, чтобы помочь генерировать идеи. Хотя каждый метод уникален в своем подходе, цель у всех одна и та же — дать толчок творчеству и разработать как можно больше креативных решений.
Погрузитесь в стадию создания идей здесь.
Этот шаблон расхождения и схождения продолжается на протяжении всего процесса дизайн-мышления при прототипировании и тестировании.