Что такое развал-схождение? Как часто нужно делать развал-схождения
Сход-развал (развал-схождение) – это регулировка колес автомобиля относительно кузова, которая предполагает два этапа: сход и развал. Именно от того, насколько правильно отрегулированы колеса, зависит управляемость машины и, как следствие, Ваша безопасность. Плохое вхождение в поворот, быстрый износ резины – это лишь некоторые последствия неграмотного выполнения развал-схождения.
Ранее регулировка колес производилась при помощи специальных свесов. Однако сегодня на смену им пришли современные стенды, оснащенные оптическими датчиками. Они позволяют провести компьютерную диагностику и получить максимально точные значения.
В этой статье Вы узнаете, что такое сход и развал и зачем они нужны, а также прочтете о том, когда стоит выполнять регулировку угла колес и почему это следует доверить опытному мастеру.
Что такое развал?
Развалом называют угол, который образуется между плоскостью колеса и вертикальной прямой. Иными словами, это отклонение колеса по вертикали.
Иными словами, это отклонение колеса по вертикали.
Положительный развал отмечается тогда, когда верхние части колес, расположенных на одной оси, находятся дальше друг от друга, чем нижние. Такой развал намеренно настраивается на грузовых автомобилях. Дело в том, что при нагрузке колеса выходят в ноль.
Об отрицательном развале говорят тогда, когда верхние части колес, размещенных на одной оси, находятся ближе друг к другу, чем нижние. Такой развал характерен для спорткаров: он позволяет максимально устойчиво входить в повороты на высокой скорости.
Когда расстояние между верхними и нижними частями колес на одной оси одинаковое, говорят о нулевом развале. Именно в этой ситуации гарантируется минимальный износ резины.
Что такое схождение?
Термином «схождение» обозначают угол между плоскостью вращения колеса и продольным сечением авто. Если передние части колес находятся ближе друг к другу, чем задние, отмечается положительное схождение
. Если задние части колес находятся ближе друг к другу, чем передние, говорят об отрицательном схождении.
Если задние части колес находятся ближе друг к другу, чем передние, говорят об отрицательном схождении.Неправильное схождение гораздо больше влияет на износ шин, чем неправильный развал.
Как понять, что регулировка углов установки колес (передних или задних) неправильная?
Неправильный сход-развал дает о себе знать следующими признаками:
- Колеса «визжат» при прохождении поворотов даже на небольшой скорости.
- Чтобы автомобиль двигался прямо, руль нужно немного отклонить влево или вправо.
- Если Вы отпустите руль, то машина начнет двигаться вправо или влево.
- Резина очень быстро изнашивается.
- Руль плохо возвращается в первоначальное положение после прохождения поворота.
На что влияет сход-развал?
Правильно отрегулированный угол колес обеспечивает Вашему автомобилю устойчивость на любом покрытии и образцовую управляемость. Также минимизируется износ шин, снижается вероятность заноса и повышается топливная экономичность.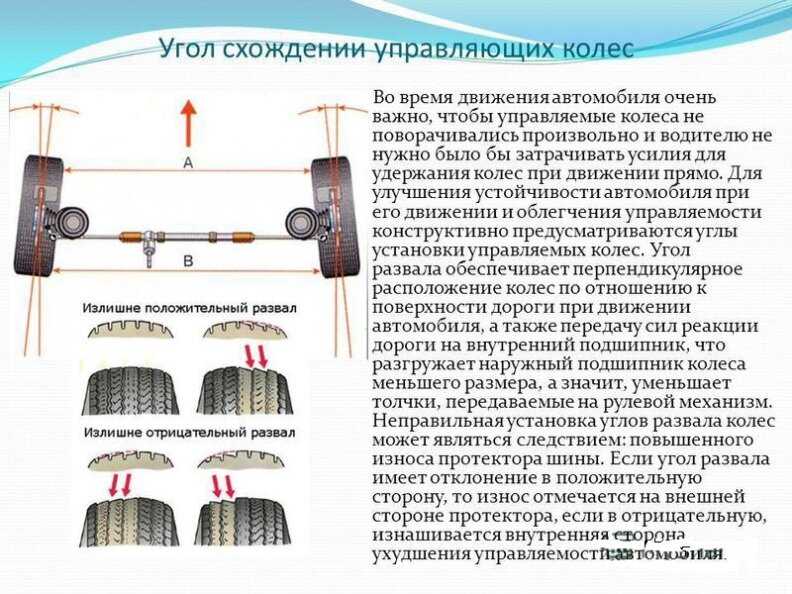
Последствия неправильного развала-схождения
Неопытные автолюбители нередко решают справиться с проблемой самостоятельно. Специалисты крайне не рекомендуют так делать, поскольку от Ваших действий зависит безопасность всех участников дорожного движения.
Если на сухом полотне авто остается более-менее управляемым, то на мокром или обледенелом покрытии его сильно «заносит» вправо и влево. Чтобы удержать машину, приходится постоянно корректировать направление движения рулевым колесом. Такое непредсказуемое поведение существенно повышает вероятность ДТП. Кстати, неправильная настройка углов колес довольно часто становится причиной выезда транспортного средства на встречную полосу и серьезных аварий.
Когда делать развал-схождение колес?
Эксперты советуют выполнять регулировку углов колес каждые 20 тысяч километров пробега. Выполнить развал-схождение внепланово придется после:
- Попадания колеса в большую яму, что привело к деформации диска.

- Изменения дорожного просвета вследствие установки укороченных пружин или «домиков».
- Замены шаровых опор, рулевого наконечника, ШРУСа.

А вот после замены шин, стабилизаторов и амортизаторов выполнять развал-схождение необязательно.
Как делают сход-развал?
Прежде чем приступить к регулировке угла колес, опытный мастер выполняет ряд подготовительных мероприятий:
- Осмотр авто, диагностика ходовой части и проверка давления в шинах.
- Определение компенсации биения обода колеса.
- Общая диагностика геометрии ходовой части. На этом этапе специалист выявляет дефекты, которые влияют на управляемость и устойчивость авто вне зависимости от развала-схождения.
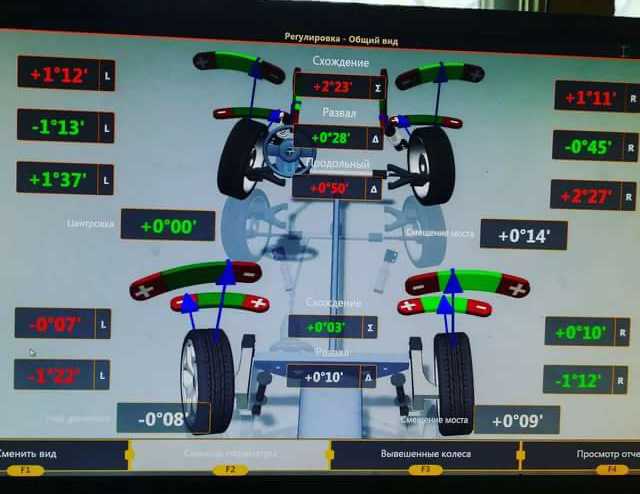
Если автомобиль успешно прошел все испытания, осуществляется регулировка развал-схождения при помощи современного оборудования. По окончании манипуляций Вы получаете распечатку с характеристиками: угол развала правого и левого колеса (для обеих подвесок) и угол схождения, угол движения авто и др.
Полный комплекс услуг по техническому обслуживанию автомобилей (в том числе и регулировка развала-схождения) оказывают специалисты автосервисов официального дилера Peugeot FAVORIT MOTORS. В нашем распоряжении – инновационная техническая база и профессиональный инструмент. Все мастера техцентров прошли аттестацию Peugeot. При выполнении работ мы используем только оригинальные запчасти и расходные материалы и руководствуемся установленным производителем регламентом. К Вашим услугам – доступные цены, интересные акции и программа лояльности.
Как делается развал-схождение осей автомобиля
Узнать о том, как делать развал-схождение, мечтают многие автомобилисты, волею судьбы оказавшиеся за городом. Что делать им, если они оказались там, где нет стенда для регулировки колёсной базы и ничего о нём даже не слышали. А знаете ли вы, что буквально несколько лет назад развал проводился своими руками и являлся обыденной операцией на автомобиль.
Регулировка развала-схождения в автосервисе
Содержание
- Информация, которую обязательно нужно знать
- Для чего это нужно
- Параметры, которые обязан знать каждый водитель
- Поперечный и продольный угол
- Инструкция — как провести операцию своими руками
- Угол схождения колёс и его регулировка
- Когда нужно проводить регулировку угла?
- Подвеска
- Новые пружины
- Клиренс
Информация, которую обязательно нужно знать
Если вдруг вы оказались в далёком населённом пункте, где отсутствует автосервис, и произошла поломка, не отчаивайтесь. Даже если нужно будет собственноручно заменить амортизатор или отремонтировать подвеску, после чего провести обязательно развал-схождение колёс, воспользовавшись этой инструкцией, можно всё проделать самому.
В первую очередь необходимо будет найти какой-нибудь гараж. Подойдёт, например, помещение бывшего совхоза, где, правда, стенда не отыскать, но линейку, хоть и стародавнюю, для регулировки угла схождения найти будет можно.
Для чего это нужно
Прежде чем провести операцию, следует знать, а зачем это нужно. Разве нельзя, не регулируя угла, доехать до ближайшего города, где в автосервисе опытные мастера за дело возьмутся? Оказывается, всё не так просто. Доехать можно, но вот каким образом? Неправильный развал приведёт к тому, что даже несколько километров езды способны привести к облысению протектора на одном колесе.
Что такое положительный и отрицательный развал-схождение
Параметры, которые обязан знать каждый водитель
Что такое развал? Не каждый автомобилист, даже проехавший много километров, это знает. А между прочим, развалом колёс называют угол, находящийся поперёк плоскости вращения и вертикалью колеса. Если этот угол будет меньше нормального значения, колесо будет направлено внутрь вертикали верхней части. Если же угол будет больше, колесо будет смотреть наружу, относительно вертикали.
Что касается схождения колёс, то им называют угол, находящийся между плоскостью вращения колеса и направления движения. Измеряется такой угол в градусах или же в миллиметрах.
Поперечный и продольный угол
Кроме вышеописанных параметров, водитель должен знать и о различных углах наклона оси.
Так, поперечным углом наклона называется величина, которая измеряется между проекцией оси поворота относительно вертикали поперечной плоскости колеса.
Напротив, продольным углом наклона оси называют величину, которая находится между вертикалью и проекцией оси поворота колеса на продольной плоскости. Такой угол ещё называют кастром, и он должен быть равен 6 градусам. И после проведения правильной регулировки кастр обеспечит самовыравнивание колёс за счёт скорости.
Инструкция — как провести операцию своими руками
Стенд регулировки развала-схождения
Для проведения операции понадобятся следующие инструменты и составляющие:
- стандартный набор инструментов автомобилиста;
- ровная бетонная площадка, желательно со смотровой ямой;
- шнур-отвес;
- линейка;
- мел.

Для начала выставляем колёса в положение прямо. Регулируем рулевым колесом, стоя сбоку автомобиля и следя за колёсами. Делаем мелом отметки сверху и снизу колеса по диаметру.
Далее, берём шнур-отвес и прикладываем его к крылу, измеряя расстояние от верхнего и нижнего края диска до места прикладывания отвеса.
Разница между величинами расстояния должна быть равной плюс/минус 3 мм.
После этого нужно будет прокатить автомобиль немного вперёд так, чтобы меловые метки повернулись на 90 градусов. Снова повторяем замер, таким же образом, как и ранее.
В видео рассказывается о том, что такое развал-схождение и как происходит регулировка:
Эта повторная процедура проводится в целях чистоты замера, ведь ни крыло, ни площадка, ни само колесо идеально ровной точкой отсчёта считаться не может.
После этого нужно будет снять колесо.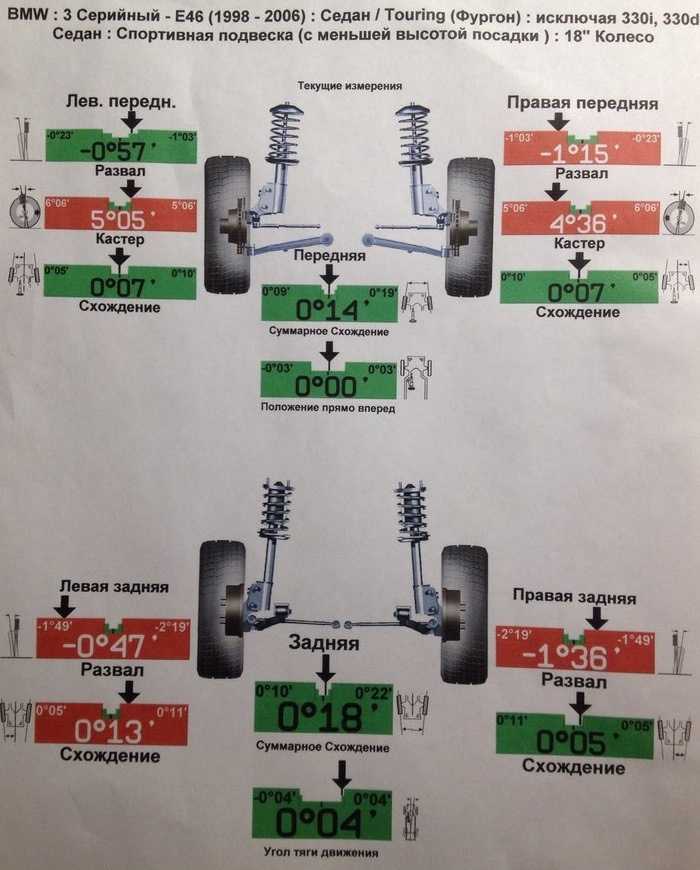
После чего колесо и кронштейн ставим на место.
Проведённая процедура поможет правильно установить угол развала колеса. И даже здесь погрешности разрешаются, но они должны быть следующими:
- на заднеприводные автомобили +1…+3 мм;
- на переднеприводные модели −1…+1 мм.
Угол схождения колёс и его регулировка
Сход-развал проводят и путём регулировки схождения колёс. Для этого используют специальную телескопическую линейку. Опять же нужно работать на идеально ровной площадке и установить колёса в направлении «прямо».
Теперь уже на внутренней стороне покрышки, ближе к диску, ставим метки мелом. Устанавливаем линейку таким образом, чтобы она не касалась никаких деталей подвески, кузова и т. п., но упиралась концами в метки. Затем линейку фиксируем. При этом «0» нужно будет сопоставить с неподвижным указателем шкалы.
При этом «0» нужно будет сопоставить с неподвижным указателем шкалы.
Видео — как правильно делается развал-схождение:
Автомобиль прокатываем немного вперёд, и линейка смещается при этом назад, опять же не касаясь никаких деталей. Проверяем показания. Если расстояние между колёсами стало меньше, нужно укоротить рулевые тяги. Если же стало больше, рулевые тяги нужно удлинить. Длина тяг регулируется с помощью специальной муфты.
Проведённая таким образом регулировка позволит благополучно добраться до ближайшего автосервиса.
Когда нужно проводить регулировку угла?
Вышеописанная инструкция поможет провести самостоятельно замеры и регулировку. Но знать, когда нужно проводить такую операцию, тоже очень важно.
Обычно после замены любой детали подвески автомобиля эта операция должна быть проведена. Незаметный невооружённым глазом крен вызывает, к примеру, замена верхней опорной чашки даже одной стойки. Около двух миллиметров даёт такой крен, а это уже повод к незамедлительной операции по регулировке угла.
Около двух миллиметров даёт такой крен, а это уже повод к незамедлительной операции по регулировке угла.
Если есть возможность, то автомобиль следует регулярно ставить на стенд, где специалисты проведут необходимые измерения. Незаметные на ощупь люфты и многое другое мастер на таком стенде быстро найдёт и предложит провести соответствующие работы.
Подвеска
Подвеска автомобиля — важная его деталь. И если даже вы ничего с ней не делаете и ездите сверхаккуратно, всё равно со временем она просядет. Из-за этого уменьшится дорожный просвет. Сама подвеска устроена таким образом, что от положения колеса будет зависеть и угол схождения и развала. Поэтому раз в год, обычно весной, опытные водители всегда проверяют и при необходимости регулируют угол развала.
Новые пружины
В случае если на автомобиль были поставлены новые пружины, развал следует отрегулировать сразу же после ремонта. А потом опять через месяц. Это делается из-за того, что дорожный просвет за это время уменьшается на два-три сантиметра.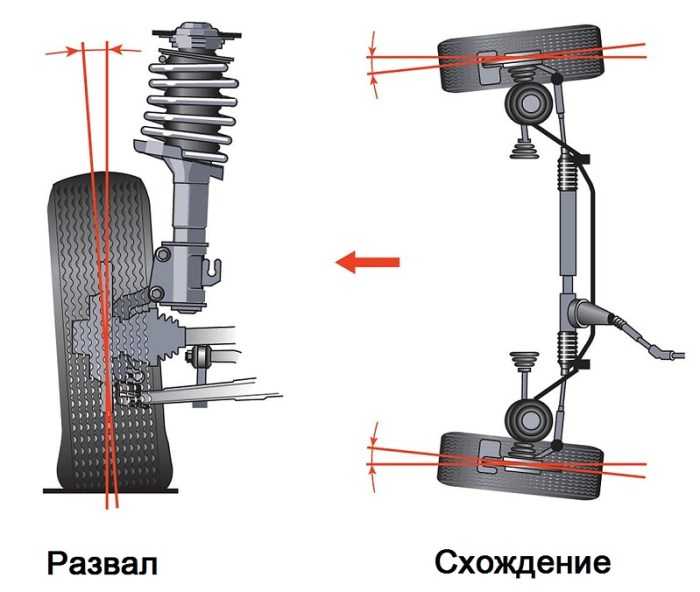 И желательно менять пружины до зимы, чтобы из-за постоянно меняющихся углов развала свести к минимуму износ протектора.
И желательно менять пружины до зимы, чтобы из-за постоянно меняющихся углов развала свести к минимуму износ протектора.
Клиренс
Регулировку углов развала следует проводить и после изменения клиренса с помощью проставок или других приспособлений. После того как колёса сменяются на размер больше или меньше, проводить развал не нужно, так как от этого углы не меняются. Но ставить на автомобиль колёса или диски разного размера крайне не рекомендуется!
Кроме того, развал-схождение принято делать, после того как на автомобиль и его заднюю ось было установлено тяжёлое оборудование весом 30 кг и больше. Или в случае когда был установлен груз весом 100 кг на переднюю ось, регулировка углов также должна быть проведена.
Вышеописанная инструкция поможет не только научиться делать развал своими руками, но и неплохо сэкономить. Как известно, цена на такие услуги в автосервисах высокая. Хотя раз год можно провести осмотр на 3D-стенде развала-схождения, где специалисты выявят неисправности.
что это, когда и как часто делать, сколько стоит регулировка углов установки колес, можно ли делать ее самому
Эдуард Солодин
недавно делал сход-развал
Профиль автора
Развал, схождение и кастер — три основных параметра углов установки колес.
Они основные, потому что их несложно проверить и отрегулировать. Есть много других. Например, аккерман — разница радиусов поворота правого и левого колеса. Дополнительные параметры углов в основном регулируют на спортивных автомобилях.
Углы установки колес влияют на устойчивость и управляемость автомобиля, а значит, на комфорт и безопасность водителя и пассажиров. Последнее особенно важно: машину с неправильными углами установки колес при экстренном торможении может увести в сторону, а системы стабилизации могут работать некорректно. Самая безобидная и частая проблема — страдает резина. Весной она опять сильно подорожала, поэтому за этим стоит следить еще тщательнее, чем раньше.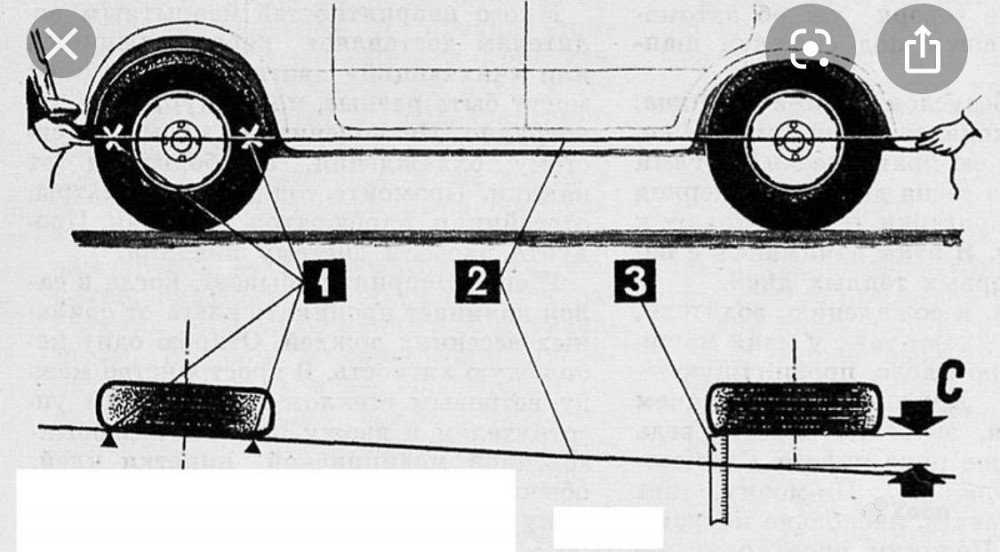
В этой статье я расскажу, что такое развал, схождение и кастер, как часто нужно регулировать углы установки колес, по каким признакам можно понять, что их параметры изменились. Кроме того, я отвечу на вопросы, можно ли сделать сход-развал самостоятельно и как выбрать хороший автосервис.
Что такое углы установки колес и на что они влияют
Развал — угол между плоскостью вращения колеса и вертикалью. Увидеть неправильный развал можно спереди или сзади машины.
Положительный развал — когда верхняя часть колеса выступает наружу относительно ступицы. Автомобиль с таким развалом с завода — это скорее всего грузовик или какая-нибудь спецтехника. Под нагрузкой колеса встают перпендикулярно плоскости дорожного полотна, развал становится нулевым.
Отрицательный развал — когда нижняя часть колеса выступает наружу относительно ступицы. Автомобиль с таким развалом более устойчив в поворотах.
Схождение — угол между плоскостью вращения колеса и продольной осью автомобиля. Неправильное схождение видно сверху или снизу автомобиля.
Неправильное схождение видно сверху или снизу автомобиля.
Положительное схождение — когда передняя часть колес обращена внутрь. Отрицательное — когда наружу.
Может показаться, что схождение должно быть нулевым, но это не так. Если сделать отрицательный развал и не компенсировать его отрицательным схождением, внутренняя сторона покрышки износится очень быстро.
/auto-album-2/
«В ее подстаканник помещается ряженка»: еще 10 автомобилей, которые мы любим всей душой
Кастер — это угол между осью поворота колеса и вертикалью. Еще его называют продольным углом наклона.
Положительный кастер — когда колесо ближе к передней части машины, чем к точке крепления стойки. Он помогает автомобилю стабилизировать управляемые колеса при наборе скорости. Проще всего представить положительный кастер на дорожном велосипеде: если набирать скорость и отпустить руль, велосипед поедет прямо. Положительный кастер — норма для современных автомобилей: особенность в том, что угол этот обычно небольшой: чаще до 6°, но может доходить до 10°.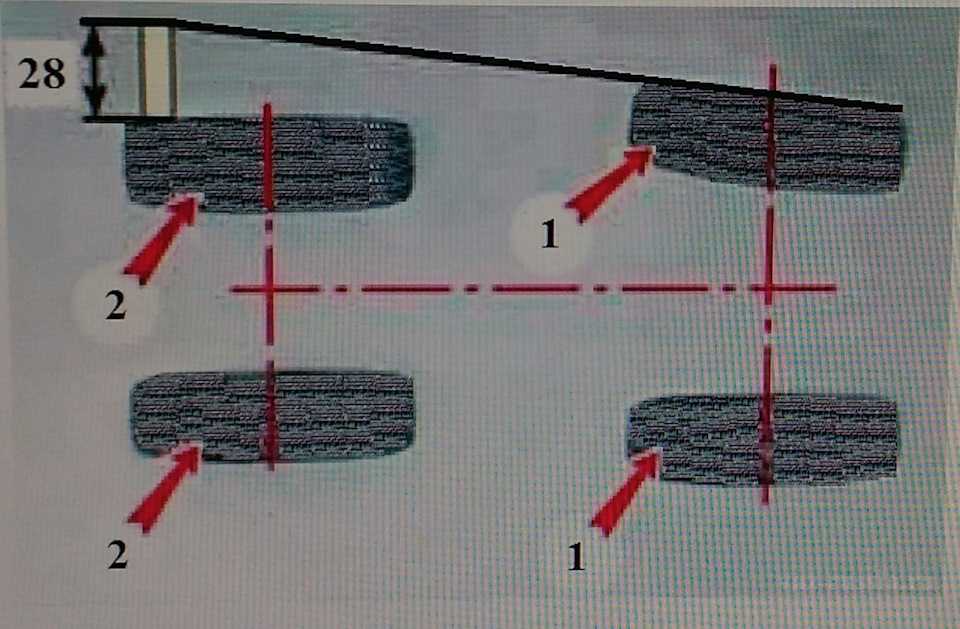
Отрицательный кастер — когда колесо ближе к точке крепления стойки, чем к передней части машины. Такой кастер у продуктовой тележки: он позволяет колесам легко крутиться вокруг своей оси, благодаря чему ее проще поворачивать в любую сторону.
Отрицательный кастер был у большинства старых автомобилей, например у Волги ГАЗ-21. Так удавалось добиться относительно комфортного управления на скорости в условиях отсутствия гидроусилителя руля. Управляемые колеса в то время стабилизировали за счет другой конструкции шин.
/7-first-auto/
«Дарит эмоции, а все остальное решаемо»: 7 историй о первом автомобиле
Автопроизводители нормируют параметры углов установки колес с учетом множества факторов: конструкции и жесткости подвески, пятна контакта с дорогой, вылета колеса, размеров шин. Настройки могут различаться даже у автомобилей одной модели — в зависимости от комплектации и типа подвески.
Какие углы можно отрегулировать, а какие нет
Не во всех автомобилях можно отрегулировать все углы колес.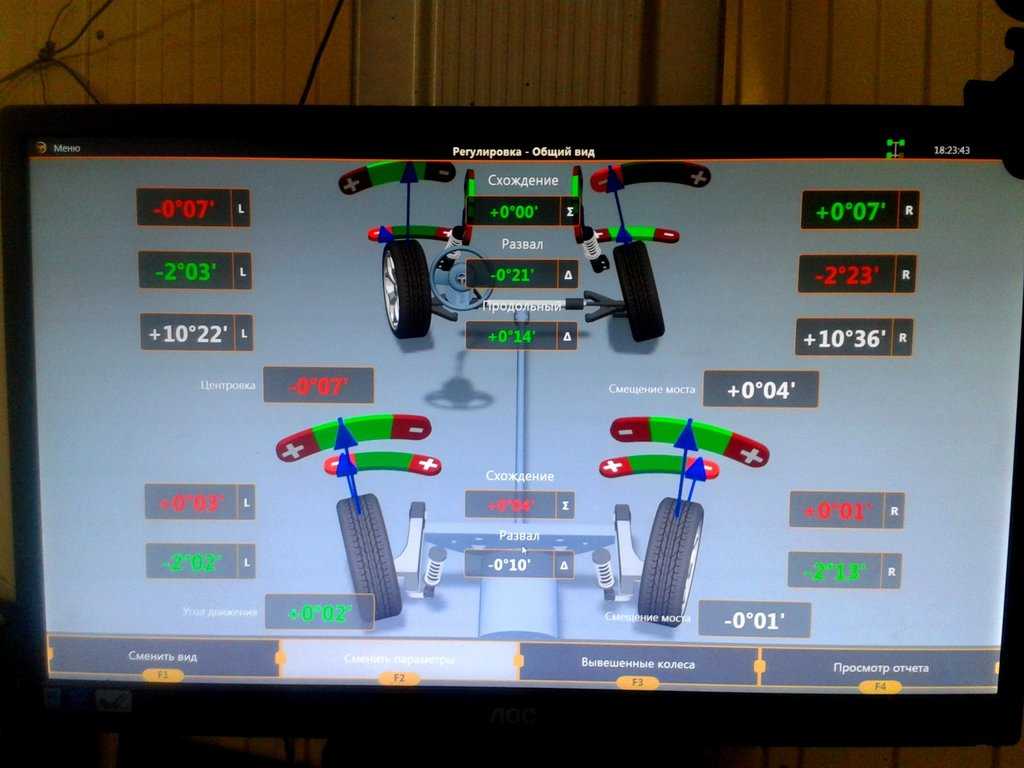 Например, если на задней оси автомобиля балка или мост, то углы задних колес не отрегулировать. Со временем они все равно изменятся по причине деформации балки. Иногда проблему пытаются решить с помощью специальных проставочных шайб под ступицу или берут другую балку с разборки, но помогает это далеко не всегда. Самый надежный, но дорогой способ — заменить старую балку на новую оригинальную.
Например, если на задней оси автомобиля балка или мост, то углы задних колес не отрегулировать. Со временем они все равно изменятся по причине деформации балки. Иногда проблему пытаются решить с помощью специальных проставочных шайб под ступицу или берут другую балку с разборки, но помогает это далеко не всегда. Самый надежный, но дорогой способ — заменить старую балку на новую оригинальную.
На подвеске типа «макферсон» в большинстве случаев не отрегулировать развал. Такая подвеска стоит на большинстве современных автомобилей.
Кастер — это исключительно про управляемые колеса, то есть почти всегда на передней оси. На задней кастер обычно нулевой. Тем не менее он может измениться после ДТП или ремонта с применением неоригинальных запчастей. Исключение — машины, у которых задняя ось может подруливать: кастер есть как параметр, но вряд ли его можно отрегулировать.
/guide/how-to-buy-new-autoparts/
Как покупать новые запчасти и расходные материалы для машины
Как делают развал-схождение
Сначала специалист должен убедиться, что подвеска полностью исправна, а давление в шинах в норме и одинаковое для колес одной оси. На разных осях оно может незначительно различаться. Обычно норму для конкретного автомобиля указывают на специальной наклейке в дверном проеме или на лючке бензобака.
На разных осях оно может незначительно различаться. Обычно норму для конкретного автомобиля указывают на специальной наклейке в дверном проеме или на лючке бензобака.
Если не выровнять давление в шинах, машину будет утягивать в сторону колеса с меньшим давлением, даже если правильно выставить углы колес. Также бесполезно регулировать углы установки колес на машине с разбитыми шаровыми или порванными сайлент-блоками рычагов.
Также не стоит выполнять эту операцию перед очередной сменой шин — развал-схождение делают на сезонной резине, так что позаботьтесь о «переобувке» заранее.
/guide/shina-s-probegom/
Как купить б/у шины для легкового автомобиля
Некоторые автомобили перед настройкой надо нагрузить. На СТО для этого часто используют канистры с водой или песком, необходимая нагрузка указана в руководстве по эксплуатации авто.
Колеса на стенде для схождения-развала наезжают на специальные поворотные круги — «пятаки», они нужны, чтобы снять нагрузку с подвески. При этом колеса не висят в воздухе: они под нагрузкой и могут менять угол. Пятаки должны свободно двигаться вдоль оси колес и вращаться. Точность измерений и качество настройки серьезно пострадают, если пятаки тяжело сдвинуть: так бывает, если они заржавели или забились песком.
При этом колеса не висят в воздухе: они под нагрузкой и могут менять угол. Пятаки должны свободно двигаться вдоль оси колес и вращаться. Точность измерений и качество настройки серьезно пострадают, если пятаки тяжело сдвинуть: так бывает, если они заржавели или забились песком.
На колеса надевают «мишени» — специальные датчики с зеркалом или стеклом. На них направляется камера и считывает положение колеса. Мишени с зажимами на колесный диск монтируются дольше и могут поцарапать металл. Более безопасный вариант — мишени с зажимами на шине.
После мастер заносит в программу развального стенда данные об автомобиле: марку, модель, поколение и комплектацию. Так стенд подстраивается под конкретный автомобиль и специалист понимает, какие углы необходимо выставить. На автомобилях с пневмоподвеской для корректного расчета углов установки колес важно измерить и внести в программу клиренс каждого колеса.
На колесном диске крепят мишень. Пятак на этом фото — прямо под колесом. Фото: Singkham / ShutterstockДалее специалист следует инструкции программы. Чтобы рассчитать угол развала колес, автомобиль прокатывают немного назад и возвращают на место. Затем вращают руль влево и вправо, чтобы программа рассчитала угол схождения. Педаль тормоза и руль после этого блокируют, чтобы убрать погрешность при настройке. Руль должен стоять ровно посередине относительно рулевой рейки.
Чтобы рассчитать угол развала колес, автомобиль прокатывают немного назад и возвращают на место. Затем вращают руль влево и вправо, чтобы программа рассчитала угол схождения. Педаль тормоза и руль после этого блокируют, чтобы убрать погрешность при настройке. Руль должен стоять ровно посередине относительно рулевой рейки.
Если углы колес выбиваются из нормального диапазона, программа сообщит об этом и выделит расхождение красным цветом.
/ford-focus-2021/
Как я купила 15-летний Форд Фокус
На рулевых тягах и наконечниках есть резьба. Если увеличивать или уменьшать их длину, можно отрегулировать схождение колес. Мастер с помощью ключей регулирует положение колес и видит на мониторе, как меняются параметры. Настройка настолько точная, что имеют значение не только градусы, но и их доли — минуты. После правильной настройки все углы колес должны находиться в зеленой зоне.
Актуальные и допустимые значения развала, схождения и кастера на мониторе развального стенда. Передняя ось, Шкода Октавия A5 2011 года. Несмотря на «макферсон», развал можно регулировать смещением подрамника. Конкретно в этом случае кастер останется красным Резьба на рулевых тягах и наконечниках позволяет регулировать схождение колес Похожий лист должны выдать, когда все настроят. В нем параметры, с которыми машина заехала на стенд, и результат работы. В этом случае развал-схождение делали на Киа Соул. Сзади балка, поэтому показания до и после примерно одинаковые
Передняя ось, Шкода Октавия A5 2011 года. Несмотря на «макферсон», развал можно регулировать смещением подрамника. Конкретно в этом случае кастер останется красным Резьба на рулевых тягах и наконечниках позволяет регулировать схождение колес Похожий лист должны выдать, когда все настроят. В нем параметры, с которыми машина заехала на стенд, и результат работы. В этом случае развал-схождение делали на Киа Соул. Сзади балка, поэтому показания до и после примерно одинаковыеКак понять, что нужно делать развал-схождение
Автомобиль при движении уводит вправо или влево. Причин может быть несколько — от уклона дороги и спущенного колеса до необходимости замены рулевых тяг или ступичного подшипника. Но чаще всего именно регулировка схождения-развала помогает вернуть правильную траекторию движения автомобиля. Проверить это легко: на загородной трассе, где мало машин, на ровном и прямом участке дороги отпустить руль и проследить за поведением автомобиля. Он должен ехать по прямой без уводов в сторону, виляний и подруливаний.
Колеса стоят прямо, руль — нет. Иногда положение руля немного смещается влево или вправо относительно центра — обычно после ремонта подвески или из-за резкого удара колесом.
Резина на колесе изнашивается неравномерно. Например, внутренняя часть колеса стерта сильнее, чем внешняя. Такое случается при отрицательном развале и схождении. При положительном изнашивается внешняя часть колеса. Чтобы не выбрасывать такую резину, в качестве оперативной меры допустимо поменять покрышки местами так, чтобы износ шел на сохранившуюся часть протектора. Но лучше отрегулировать углы установки колес и избавиться от этой проблемы.
/guide/rezina/
Как подобрать резину для легкового автомобиля или кроссовера
Из-за проблем с развалом-схождением внутренняя часть шины стерлась до кордаКак часто нужно делать развал-схождение
Сезонно. В идеале развал-схождение нужно делать при сезонной смене шин. Особенно если на разные сезоны у вас колеса с разными параметрами. Например, на лето — 19 дюймов с низкопрофильной резиной, на зиму — 17 дюймов с обычной.
Особенно если на разные сезоны у вас колеса с разными параметрами. Например, на лето — 19 дюймов с низкопрофильной резиной, на зиму — 17 дюймов с обычной.
По пробегу. Сход-развал рекомендуют делать каждые 20 000 км. Естественный износ деталей подвески может привести к изменениям углов установки колес.
По необходимости. Если автомобиль попал на скорости в яму, настройки тоже могут сбиться. Когда после этого машину начинает уводить в сторону, резина изнашивается неравномерно, изменилось положение руля — необходимо делать схождение-развал.
/serious-damage-stories/
«Повезло еще, что не встали на трассе»: 10 историй о серьезных поломках автомобиля
После ремонта ходовой. Там одни компоненты влияют на углы установки колес, другие — нет, но делать развал нередко приходится в любом случае. Вот пример: стойки стабилизатора не должны ни на что повлиять, но есть машины, на которых для этого приходится снимать подрамник, — а значит, придется делать развал-схождение.
Также важно помнить, что неоригинальные детали могут отличаться от оригинальных по геометрии. Из-за них могут серьезно сбиться настройки, которые не отрегулировать.
Можно ли отрегулировать развал-схождение самому
Теоретически — можно попытаться. Но все же рекомендую обратиться в сервис, где есть необходимое оборудование. Электронные измерения очень точные, в них параметры отслеживаются до долей градуса — минут. При самостоятельном измерении погрешность может быть большой. Кроме того, перед этим необходимо узнать заводские параметры подвески.
Обычно в гаражных условиях для настройки углов натягивают нить по длине машины параллельно колесам. Далее выставляют колеса ровно и измеряют расстояние от диска до нити в двух точках, если оно разное, это колесо нужно отрегулировать.
8 узлов и жидкостей в авто, которые стоит контролировать после окончания гарантии
Еще один, дедовский, способ регулировки схождения-развала — приставить к диску уровень и посмотреть, насколько отклоняется пузырек воздуха в жидкости.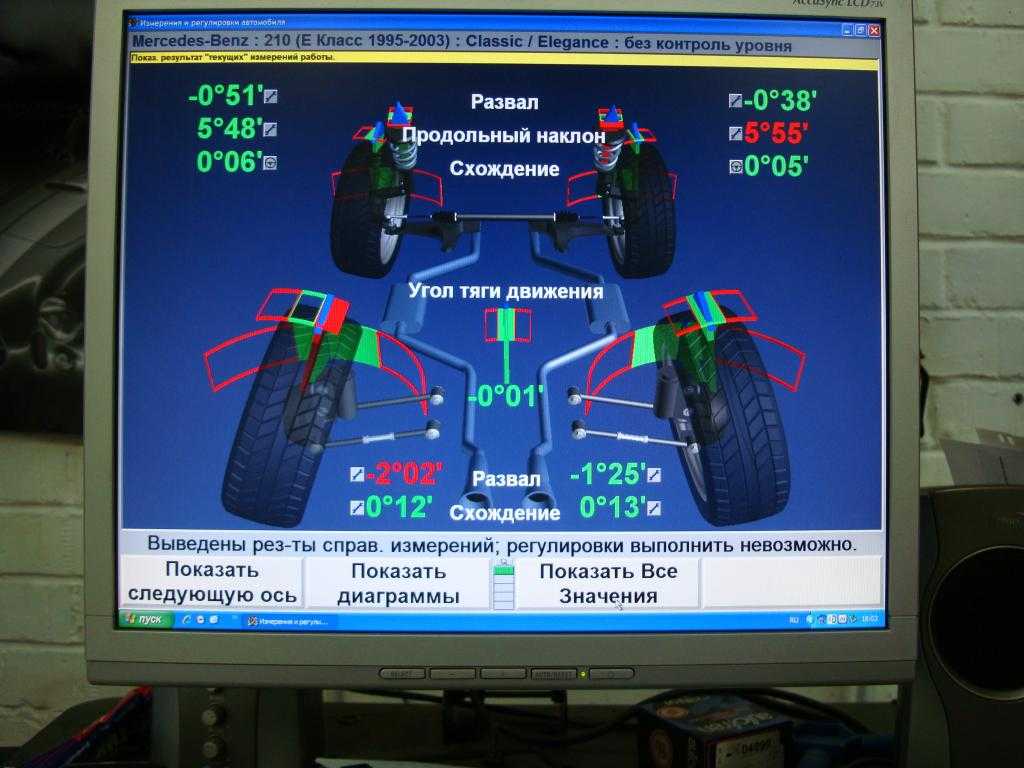 Такая настройка тоже приблизительна и допустима только в том случае, если нет возможности обратиться в профессиональный сервис.
Такая настройка тоже приблизительна и допустима только в том случае, если нет возможности обратиться в профессиональный сервис.
Как выбрать СТО
Диагностика подвески — первое, что предложат на хорошей СТО. Если в ходовой части автомобиля есть какие-то люфты, которых не должно быть, то схождение-развал делать бессмысленно.
Калибровка стенда. Для точной диагностики и настройки стенд для развала-схождения должен быть откалиброван. Спросите в автосервисе, когда последний раз делали калибровку стенда, есть ли подтверждающие документы. Такую калибровку надо проводить регулярно, но некоторые СТО на этом экономят. Совсем здорово, когда у СТО есть свое оборудование для калибровки.
Опытный мастер. Хороший результат зависит от мастера. Недостаточно ввести в программу название марки и модели автомобиля, на точность настройки может влиять даже год выпуска и маркировка кузова. Неопытные настройщики могут это не учесть.
Хороший мастер спросит, когда ремонтировали подвеску, какие запчасти использовали, проверит состояние резины и расспросит о поведении машины на дороге. Также он убедится, что руль стоит ровно.
Также он убедится, что руль стоит ровно.
/guide/detailing-in-details/
Автомобильный детейлинг: что это такое, какая от него польза
Если на автомобиле установили нештатные колеса или тюнинговали подвеску, то стандартные нормативы углов для этой модели уже не подходят. Поэтому схождение-развал для таких авто должен делать мастер с большим опытом, который не будет ориентироваться только по зеленым зонам на мониторе развального стенда.
Бывает, что хороший специалист сможет выставить углы в тех случаях, когда другие мастера пасуют, — просто потому, что знает особенности конкретной марки или модели. Например, посоветует купить особенные болты взамен тех, что поставили при ремонте подвески просто на глаз.
Документы и гарантия. Хорошие автосервисы дают гарантию на свою работу и предоставляют клиенту не только кассовый чек, но и распечатку параметров углов колес до и после регулировки. Это нужно прежде всего мастеру: когда автомобиль в следующий раз заедет на стенд, он уже будет знать предысторию.
Стоимость услуг по регулировке углов колес зависит от уровня оснащенности СТО и региона, в котором расположен сервис. Ориентировочно это 1500—3500 Р.
Запомнить
- Если на автомобиле стоят нештатные колеса или тюнинговали подвеску, то стандартные нормативы углов установки колес для этой модели не подходят.
- Во многих случаях нельзя настроить какой-то угол установки. Иногда это все углы сразу.
- Записывайтесь на развал-схождение, если авто при движении уводит в сторону, неравномерно стираются шины или колеса стоят прямо, а руль криво.
- Иногда эти признаки вызваны другими причинами: разным давлением шин на одной оси, неправильной установкой руля или изношенной подвеской.
- Проверяйте углы установки колес каждые 20 000 км пробега, при попадании в глубокие ямы, после ремонта подвески и при сезонной смене колес, если у комплектов разные параметры.
- Заказывайте развал-схождение в сервисе: даже если дело будет только в резине, экономить не получится.

Регулировка развала схождения. Сход развал своими руками. Советы и рекомендации как самому сделать развал схождение колес
Ни для кого не станет новостью, что неверно налаженный сход развала колеса, может привести не только к ухудшению качества покрышки, но и к большому расходу топлива. Именно поэтому, к выставлению схода развала стоит подойти ответственно.
Своими силами настроить сход развал совсем не сложно, как может показаться сначала. Мы попытаемся рассмотреть этот вопрос подробно и дать оптимальные советы новичкам механикам. Стабилизация пары управляющих колес – это тот самый важный аспект, который влияет на устойчивость машины на дороге. Что это значит? Колеса должны двигаться по прямой линии, а минуя поворот возвращаться в исходное положение.
Следуя из этого, острая необходимость процедуры стабилизации колес разъясняется очень просто. Когда автомобиль двигается, колеса, которые не стабилизированы, уходят в сторону в результате толчков от дороги. Тогда водитель должен возвращать колеса в нужное (прямолинейное) положение. Учитывая то, что это происходит постоянно, человек за рулем сильнее устает. К тому же, контакты рулевого привода быстрее износятся. А с увеличением скорости, растущая неустойчивость становиться не безопасной.
Тогда водитель должен возвращать колеса в нужное (прямолинейное) положение. Учитывая то, что это происходит постоянно, человек за рулем сильнее устает. К тому же, контакты рулевого привода быстрее износятся. А с увеличением скорости, растущая неустойчивость становиться не безопасной.
От чего зависит стабилизация управляемых колес? Ответ простой: от их схождения или развала. Регулировка схода развала колес может быть произведена в автомастерских, но вполне возможно решить эту проблему и своими руками.
Признаки что нужно регулировать сход развал
Первое, что необходимо сделать, это определить необходимость регулировки схода развала.
Рассмотрим это по пунктам:
- Непрерывный уход авто от заданного курса прямолинейного движения в ту или иную сторону.
- Неоднородная изношенность покрышек.
- При осмотре желобка протектора переднего колеса вдоль оси вращения, необходимо осмотреть края этого желобка. Кромки одинаковые – это значит, что нет причин для беспокойства, если же одна из них имеет некоторую заостренность, а другая – нет, значит у вас есть проблема. Но на это стоит обращать внимание лишь при спокойной езде. Если же вы являетесь поклонником быстрой скорости, то это условие может быть обманчивым.
- Трудность управления при маневрах.
 Но на это стоит обращать внимание лишь при спокойной езде. Если же вы являетесь поклонником быстрой скорости, то это условие может быть обманчивым.
Но на это стоит обращать внимание лишь при спокойной езде. Если же вы являетесь поклонником быстрой скорости, то это условие может быть обманчивым.Наличие хотя бы одно из таких симптомов говорит, что нужно устанавливать развал схождения. Водители имеющие некоторый опыт в ремонте авто своими руками при большом желании могут выполнять сход развал самостоятельно.
Как регулируется сход развал?
Для ремонта вам будут необходимы:
- линейка;
- мел;
- стандартный набор инструментов;
- шнур с отвесом;
- ровная площадка с ямой или подъемником.
Сначала потребуется выяснить: насколько точно было произведено схождение раньше. Т.е. «нулевое» ли положение у рулевой рейки при прямолинейном движении. Как это сделать? Следуем дальнейшим указаниям:
- Поставить автомобиль на ровной поверхности.
- Затем повернуть максимально руль в одну сторону, сделав метку сверху на руле (посередине круга) повернуть руль до упора в другую сторону. При этом необходимо посчитать количество целых оборотов и частей целой окружности (долей).
- Когда посчитали поделить полученное количество на 2 и повернуть руль в это положение.
 При этом необходимо посчитать количество целых оборотов и частей целой окружности (долей).
При этом необходимо посчитать количество целых оборотов и частей целой окружности (долей).Если данный результат совпадает с привычным положением руля, то «нулевое» положение рейки выставлено. Если нет, это придется сделать самим.
Как выставить «нулевое» положение?
Необходимо снять руль, для этого отвинтите гайку. После зафиксировать его в посчитанном нами «нулевом» положении (спицы руля должны располагаться симметрично). Теперь мы будем ориентироваться по этому положению. Дабы себя проверить, нужно поочередно вращать руль влево/право — в обе стороны он должен поворачиваться на одинаковое количество оборотов, по этому поворачивая колесо до предела в стороны, подсчитывайте их.
Далее нужно ослабить стопорные гайки наконечников рулевых тяг. Одну тягу следует немного выкрутить, а вторую закрутить на такое же самое количество оборотов (это очень важно!). Такую процедуру можно сделать один раз и более не менять положение руля.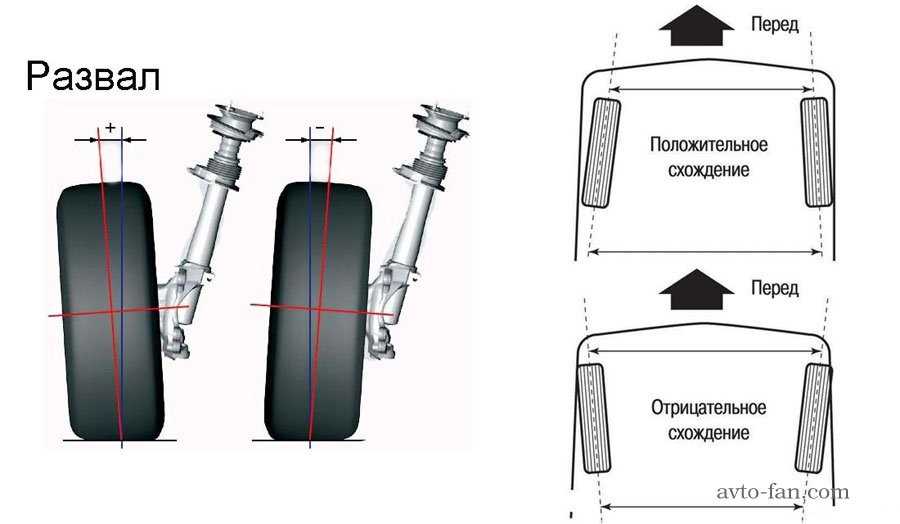 А в дальнейшем – лишь регулировать схождения.
А в дальнейшем – лишь регулировать схождения.
Как отрегулировать схождения колес?
После проверки прямолинейности нужно проверить степень загруженности транспорта, давления в покрышках, надежно ли крепление подвески и механизма руля на предмет наличия стука при повороте руля. После этого уже можно приступить непосредственно к проверке и настройке схождения.
Для определения уровня схождения колес, следует вычислить разницу между точками на ободе спереди и сзади его оси геометрии. Для этого нужно использовать специальную цепь с линейкой или натяжной прибор.
Чтоб измерить схождение линейка устанавливается меж колес, таким образом, чтоб наконечники труб уперлись в бок покрышек, а цепочки дотрагивались до земли. Когда вы установите стрелку на нулевое положение, машину следует немного перекатить вперед, чтобы линейка очутилась сзади оси колес. При этом стрелка должна показывать уровень схождения. В случае несовпадения с нормой она должна быть откорректирована.
Для того, чтобы отрегулировать схождение колес нужно вращать соединительные муфты боковых рулевых тяг. Когда эта операция проведена, контрольные гайки необходимо надежно затянуть.
Регулировка угла развала колес
Самым сложным процессом выступает проверка и регулировка развала колес, но и ее возможно выполнить своими силами. Чтоб это сделать машина поднимается так, чтоб колеса не дотрагивались до земли. После этого нужно вычислить места одинакового биения на боковых частях шин. Выставив колеса в положение движения по прямой, рядом с колесом следует подвесить груз. Мелом делаются метки по окружности колеса сверху и снизу. С помощью шнура с отвесом вычислите дистанцию от обода до шнура.
Разница дистанций между нитью груза и верхней частью обода и есть уровень развала.Для точности выполнения процедуры прокатите машину, чтоб колесо повернулось на 90?.. Повторить несколько раз и записать результаты.
Далее снимаем колесо автомобиля и отпускаем 2 болта крепления кронштейна стойки амортизатора к поворотному кулаку. Затем сдвигаем вовнутрь или наружу поворотный кулак, в каком направлении, и на какое расстояние, зависит от результатов ваших замеров. Именно таким образом вы сможете установить необходимый угол развала. После процедуры нужно подтянуть болты, поставить колесо и вновь провести замеры.
Затем сдвигаем вовнутрь или наружу поворотный кулак, в каком направлении, и на какое расстояние, зависит от результатов ваших замеров. Именно таким образом вы сможете установить необходимый угол развала. После процедуры нужно подтянуть болты, поставить колесо и вновь провести замеры.
Помните, что на автомобилях с задним приводом допускают норму угла развала передних колес, где-то в пределах +1 — +3 мм, а у машин с передним приводом такая норма равна от -1 до +1 мм.
После завершения всей процедуры, не забывайте проверять затяжку всех тех болтов, которыми вы проводили регулировку. А в после завершения регулировки развала схождения проверьте выравнивание автомобиля на дороге.
Делая сход-развал собственноручно, помните, что необходимо проводить замеры несколько раз (не меньше трех), после чего взять среднеарифметическое значение. Если развал-схождение отрегулированы правильно, транспортное средство не будет уходить в сторону при движении, а износ протектора шин будет равномерный.
Вся процедура регулировки проводится заново в том случае, если после проведенных работ машина всё равно «уходит» с траектории прямолинейного движения. О неправильном развале или схождении также скажет неравномерный износ покрышек, по этому диагностика шин также будет не лишней.
Самостоятельное выполнение такой нелегкой процедуры сэкономить приличную сумму денег, однако помните, что для большинства современных автомобилей рекомендуется проведение сход/развал в автосервисах. Дополнительно вы можете посмотреть обучающее видео, как самому сделать развал схождение тут.
Три расхожих заблуждения о развал-схождении колес — Лайфхак
- Лайфхак
- Эксплуатация
Фото www.multiscreensite.com
Даже те автовладельцы, кто по жизни с техникой только на «вы», вынуждены иметь хотя бы отдаленное представление о характере профилактических работ, которые периодически требуется проводить с машиной. Ведь речь идет не только о здоровье «железного коня», но и о безопасности самого водителя и его пассажиров. Например, о такой важной процедуре, как регулировка углов развал-схождения колес, среди автомобилистов ходит много разных мифов, самые распространенные из которых развенчал портал «АвтоВзгляд».
Например, о такой важной процедуре, как регулировка углов развал-схождения колес, среди автомобилистов ходит много разных мифов, самые распространенные из которых развенчал портал «АвтоВзгляд».
Иван Флягин
Все четыре колеса на автомобиле должны быть установлены под определенным углом. Если мы посмотрим на машину спереди или сзади и увидим, что колеса расположены не строго параллельно друг-другу, а под значительным углом, то у них не отрегулирован развал. А если посмотреть на машину сверху и заметить аналогичную неровность, то очевидно, что у колес нарушено схождение.
Правильная настройка углов установки колес, что в обиходе и называется «развал-схождением», обеспечивает при движении автомобиля оптимальный контакт шины с поверхностью дороги. От этого зависит не только преждевременный износ «резины», но самое главное — устойчивость машины и ее управляемость, а следовательно — безопасность дорожного движения.
Миф 1: раз в сезон
Не верьте официальным сайтам автосревисов, которые рекомендуют регулировать развал-схождение строго раз в сезон. Чем чаще к ним будут обращаться клиенты, тем им выгодней. Но это имеет смысл только в одном случае — когда у летних и зимних колес разный размер. Например, если летом ваш автомобиль обут в низкопрофильные 19-дюймовые шины, а зимой — в практичные 17-дюймовые, вам действительно придется тратиться на развал-схождение раз в межсезонье. А при одинаковых размерах сезонных покрышек регулировать углы необязательно.
Чем чаще к ним будут обращаться клиенты, тем им выгодней. Но это имеет смысл только в одном случае — когда у летних и зимних колес разный размер. Например, если летом ваш автомобиль обут в низкопрофильные 19-дюймовые шины, а зимой — в практичные 17-дюймовые, вам действительно придется тратиться на развал-схождение раз в межсезонье. А при одинаковых размерах сезонных покрышек регулировать углы необязательно.
Миф 2: самостоятельная настройка
Многим приходилось слышать байки, как водители старшего поколения в советские времена умудрялись своими силами настраивать углы установки колес у своих «ласточек». Но речь в таких случаях идет о «Жигулях» или старинных иномарках с простой подвеской.
Самостоятельно сделать развал-схождение в современных машинах где-нибудь в гараже у подавляющего большинства автовладельцев не получится. Для этого требуется специальное оборудование и умение им пользоваться, поэтому лучше не экономить на такой процедуре и не отдавать машину всякого рода гаражным мастерам.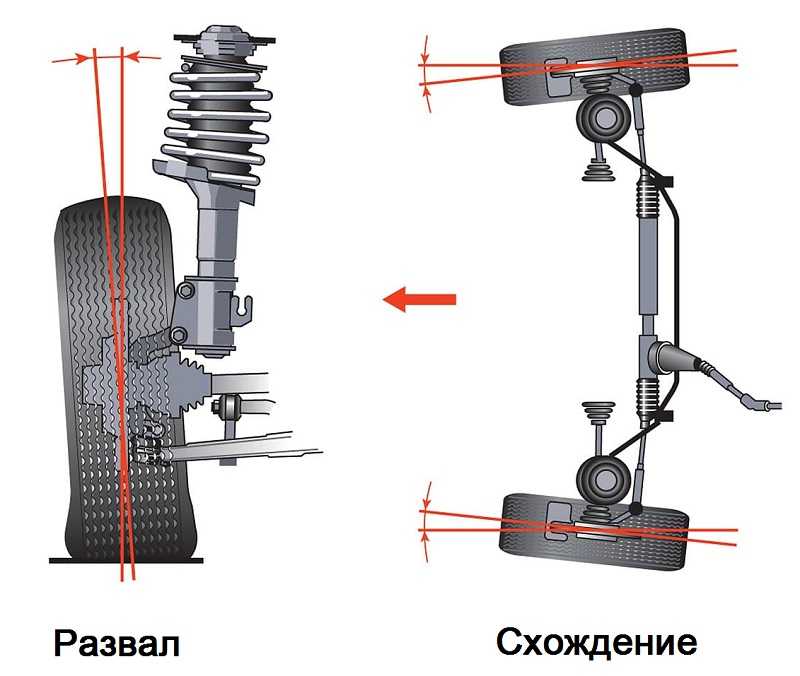 К тому же не стоит забывать, что перед регулировкой рекомендуется пройти полноценную диагностику подвески.
К тому же не стоит забывать, что перед регулировкой рекомендуется пройти полноценную диагностику подвески.
Миф 3: идеальная настройка — 0 градусов
Как уверяют эксперты, «нулевой» угол развала обеспечивает максимальное пятно контакта колеса с дорогой только в положении руль прямо. То есть в этом случае на прямой траектории машина управляется оптимально. Однако при повороте колесо наклоняется на несколько градусов, пятно контакта уменьшается, и складывается противоположный эффект: машина уже менее устойчива и хуже тормозит. Так что идеальные углы колес на «легковушках» действительно близки к нулю, но редко, когда совпадают с этим параметром.
142886
Для каждой конкретной модели размеры рассчитываются отдельно в зависимости от ее массы, габаритов, технических характеристик двигателя, подвески, тормозной системы, предполагаемых режимов эксплуатации автомобиля и многого другого.
В программное обеспечение специального компьютерного оборудования для регулировки развала-схождения заложены заводские параметры определенных моделей, и мастеру остается выбрать нужные настройки.
Когда необходима регулировка
Самым распространенным признаком неотрегулированного развал-схождения считаются неравномерно стертые шины с наружной или внутренней стороны. Обычно это сопровождается следующим явлением: во время движения по ровной дороге машина «рыскает» или ее тянет в сторону, несмотря на то, что руль удерживается в прямом положении. В случае торможения автомобиль также заметно уводит в бок или даже заносит. Иногда при поворотах руль тяжелеет и требует дополнительного усилия. Все это можно считать явными сигналами для необходимости проверить у специалистов настройки угла колес.
Кроме того, регулировка развал-схождения требуется после замены рулевых тяг или наконечников, стоек стабилизатора, рычагов, ступичных или опорных подшипников, шаровых опор или после любого другого ремонта ходовой части, затрагивающего эти узлы.
- Автомобили
- Прайс-лист
Выбираем доступную премиальную машину для VIP-персоны на вторичке
20995
- Автомобили
- Прайс-лист
Выбираем доступную премиальную машину для VIP-персоны на вторичке
20995
Подпишитесь на канал «Автовзгляд»:
- Telegram
- Яндекс. Дзен
безопасность дорожного движения, колеса, автосервис, технология, ремонт, техническое обслуживание
Сход/развал передняя ось — Статьи
Сход/развал передняя ось представляет собой регулирование угла положения передних колёс относительно вертикальной плоскости. Нарушение развала провоцирует снижение управляемости авто и увеличению износа шин. Техническим регламентом предусмотрено проведение регулировки схода/развала колёс при любом вмешательстве в подвеску транспортного средства.
Что представляет собой развал/схождение
Конструкция подвески гражданского легкового автомобиля представляет собой набор тщательно сбалансированных между собой узлов и деталей. Немалую важность при этом имеет геометрическое положение передних колёс, ввиду осуществления ими функций управления движением автомобиля. Одно из распространённых понятий в среде автомехаников — регулировка развала и схождения передних колёс, заключающееся в выставлении оптимального угла положения колеса относительно вертикальной оси.
Существуют 2 основных типа регулировки: это угол развала (camber) и схождения (toe) колеса.
Развал передних колёс
Этот показатель представляет собой значение угла продольной оси колеса. При отрицательном развале происходит заваливание колеса внутрь, при положительном — наружу. Но в идеале колёса должны стоять практически перпендикулярно поверхности. Развал колёс автомобиля важен по многим причинам:
неправильная регулировка создаёт излишнее давление на ступичный подшипник, что приводит к быстрому выходу его из строя; при неправильном развале колёс движущийся по неровному покрытию автомобиль теряет управляемость, поскольку пятно контакта шины с дорогой становится нестабильным. Но это во многом зависит от конфигурации подвески авто.
В случае с распространённой среди большинства легковых автомобилей подвеской МакФерсон показатель развала может приобретать небольшие отрицательные значения. Характерный пример этому — расположение колёс гоночных автомобилей, в верхней части сильно заваленных внутрь. Сделано это с целью обеспечения максимальной управляемости: при вхождении в поворот возникает крен подвески, приводящий к изменению значения развала колёс в сторону положительного. Это приводит к снижению пятна контакта, и при входе в поворот на высокой скорости провоцирует вхождение в неуправляемый занос. Изначально отрицательный развал в случае крена изменяется на нулевой, что позволяет сохранить управление над авто. Но при этом наблюдается сильный износ резины при движении по прямой.
Для каждой конфигурации подвески регулировка развала колёс осуществляется в особом порядке. В случае с популярной МакФерсон регулировка осуществляется путём смещения стойки амортизатора — с этой целью отверстие для крепления эксцентрикового болта в нижней части стойки имеет овальную форму. Но стоит отметить, что ряд современных автомобилей выпускается без возможности регулировки развала. В этом случае отклонение его от установленных производителем норм может означать износ сайлентблоков, резиновых втулок подвески либо деформацию кузова, вызванную ДТП.
Схождение передних колёс
Как и развал, схождение может быть положительным или отрицательным. Под схождением понимается параллельное размещение колёс относительно оси движения авто. При положительном схождении их передние кромки немного «смотрят» друг на друга, при отрицательном — разведены по сторонам.
Схождение является одним из наиболее важных параметров подвески авто, от которого напрямую зависит управляемость транспортным средством.
Стоит отметить, что при неправильном схождении передних колёс значительно сокращается срок службы сайлентблоков.
Ранее в среде автолюбителей бытовало ошибочное мнение, что схождение было разработано инженерами для компенсации развала колёс. Однако фактически эти параметры существенно разнятся между собой и единственный фактор, объединяющий их вместе — необходимость регулировки после проведения ремонта подвески.
Как показала практика, при отрицательном схождении чувствительность рулевого управление несколько возрастает, но устойчивость транспортного средства при этом снижается. Положительные значения схождения колёс делают автомобиль более устойчивым на дороге, особенно это заметно при движении по неровным покрытиям. Но при высоких значениях наблюдается повышенный износ резины.
Когда нужна регулировка развала/схождения
Необходимость регулировки угла положения передних колёс возникает в следующих случаях: 1. При вмешательстве в узлы и детали подвески с целью их ремонта или замены. В эту категорию входят работы по замене амортизаторов, шаровых шарниров, рулевых наконечников, тяг, рейки, сайлентблоков, рычагов в сборе и пр. 2. В случае участия машины в ДТП либо наезда на высокой скорости на лежачий полицейский, бордюр, попадание колеса в глубокую яму. 3. Специалисты автосервисов также рекомендуют проводить замер и корректировку развала/схождения при сезонной смене резины.
Движение на машине с неправильно выставленными значениями угла колёс чревато следующими последствиями:
потерей устойчивости транспорта на дороге;
снижением чувствительности и чёткости управления;
«уводом» транспортного средства в сторону при торможении или отпускании руля;
быстрым выходом из строя сайлентблоков и втулок подвески;
увеличенным износом резины.
Важно знать, что регулировка параметров для передней и задней оси автотранспортного средства должна выполняться на специализированном стенде. Любые попытки провести регулировку «на глаз» с использованием подручных методов обычно приводят к ещё большему отклонению от нормы. Следует помнить, что изменение параметров всего на 0,5 градуса уже является сильным нарушением, отрицательно влияющим на управляемость автомобиля.
Как подготовиться к развалу/схождению
Стоит отметить, что существует ряд минимальных требований, необходимых к выполнению для проведения регулировки развала и схождения передних колёс.
1. На автомобиле должны быть установлены диски с одинаковыми значениями диаметра, вылета и ширины.
2. Резины должна быть с приблизительно равным значением износа, одинакового типоразмера.
3. Давление в шинах должно соответствовать установленным значениям.
4. В подвеске должен отсутствовать люфт, вызванный неисправностью отдельных узлов. Втулки тяг, сайлентблоки, рычаги, наконечники и шаровые опоры обязаны быть полностью исправны.
Внимание! Если после регулировки развала схождения наблюдается увод машины в сторону, то необходимо поменять передние колёса местами — обычно подобное поведение автомобиля связано с неравномерным износом колёс, возникшим вследствие эксплуатации авто с неотрегулированной подвеской.
Во время регулировки развала/схождения рулевое колесо устанавливается в центральное положение. Если с течением времени при движении автомобиля по прямой наблюдается отклонение руля, то необходимо повторно провести регулировку развала.
Сервис Uremont.com поможет найти автомастерскую, осуществляющую все виды работ по ремонту и настройке подвески — вам нужно просто оставить заявку на сайте. Ремонт авто с нами — недорого, быстро и удобно.
Как работает Uremont?
01
Создаете заявку
с кратким описанием работ и желаемой датой ремонта. Потратите не более 3 минут
02
Получаете предложения
от специализированных автосервисов в личном кабинете
03
Сравниваете ответы
наиболее подходящие по стоимости, отзывам, местоположению и другим параметрам
04
Подтверждаете запись
а также все условия ремонта и можно смело ехать в автосервис
Создание заявки абсолютно бесплатно и займет у вас не более 5 минут
Создать заявку
Как проверить и отрегулировать развал? Схождение и развал колес что за развал колес колеса
Процедура регулировки развала схождения колес известна сегодня и людям далеким от автомобильного мира. Тем не менее, не все понимают, чем вызвано схождение, в чем его важность и когда необходимо проверить и отрегулировать развал схождения колес. Об этом мы поговорим в этой статье.
Развал и схождение колес (или как его еще называют биговка колес), это углы их установки, и значения этих углов будут разными для различных моделей автомобиля. Развалом колеса называют угол наклона колеса по отношению к дорожному полотну. При наклоне наружу говорят о положительном схлопывании, при наклоне внутрь — обрушении называют отрицательным. Чрезмерно положительный или отрицательный развал приводит к быстрому износу резины, однако в автоспорте используется отрицательный развал — он позволяет увеличить остроту реакции на руль, а для внедорожников иногда используют положительный угол развала.
Развал-схождение — это разница между расстояниями между передней и задней точками передних колес. Другими словами, это горизонтальный угол их установки. Схождение положительное, если расстояние между передними точками колесных дисков меньше, чем между задними, если же это расстояние больше, говорят об отрицательном схождении колес. Также имеется угол продольного наклона шкворня или колеса. Его неравномерные значения могут привести к затруднениям в движении за рулем и общему снижению устава автомобиля в поворотах. Ну и еще один важный теоретический момент, это то, что развал схождения, как собственно и кастер, устанавливается только на передние колеса автомобиля.
Когда и для чего нужно производить развал
Регулировка развала схождения проводится в условиях нашей действительности примерно каждые 15 — 20 тыс. пробега для отечественных автомобилей, и каждые 30 35 тыс. пробега для иностранных машины. Но, это, так сказать, плановая проверка, а между тем, в некоторых случаях проверка и корректировка схода на развал и до установленного срока. Среди таких случаев можно отметить следующие:
- яма на дороге или другой сильный удар по ходовой части и подвеске;
- ремонт или замена шаровых опор, сайлентблоков, рычагов и тд;
- ремонт рулевой рейки или замена рулевых наконечников
- высокая степень износа шин;
- проблемы с управляемостью автомобиля или его удержанием на прямой траектории движения;
- необоснованно быстрый износ шин;
- изменение дорожного просвета автомобиля;
Что дает правильная установка схода развала и кастора?
- увеличенный срок службы шин;
- высокая степень управляемости машины в поворотах и разворотах;
- стабильное поведение автомобиля на дороге;
- повышенная отзывчивость автомобиля на команды руля;
- небольшое снижение расхода топлива;
Важность правильной установки развала схождения колес можно выразить двумя словами — безопасность и экономия. Поэтому пренебрегать этой процедурой ни в коем случае не стоит.
Как сделать сход-развал
Сегодня проверка и регулировка Сборка развала производится на СТО, оборудованных специальными стендами. Наиболее распространены сейчас оптические и компьютерные стенды для регулировки развала-схождения. Споры о том, где лучше производить такую регулировку, не первый год не субсидируются. Скажем, все зависит от уровня мастерства и добросовестности специалиста, выполняющего эту процедуру. Неоспоримым преимуществом компьютерных стендов является регистрация положения задних колес в процессе регулировки развала-схождения. Однако на оптических стендах можно выставить практически идеальные углы поворотов колес. Но перед регулировкой развала схождения следует убедиться, что передние шины отбалансированы и ходовая работает исправно. Иначе регулировать развал схождения нет смысла. После ремонта или замены необходимых узлов процедуру придется повторить еще раз. И должного эффекта такая регулировка при наличии проблем с ходовой или подвеской не даст. Если вы не уверены, является ли причиной возникших проблем поломка развала схождения, или причина в чем-то другом, то пройдите проверку, конечно же стоит.
Помимо вышеописанной процедуры проверки, сбор развала, проводимый опытным специалистом, позволяет определить, побывал ли автомобиль в дорожно-транспортном происшествии. Ибо, нарушение взаимного расположения лонжеронов, искривление геометрии кузова и прочие последствия ударов, на первый взгляд очень незаметны. Однако не отразиться на углах колес они не могут.
В случае, если вы во время езды зацепили достаточно глубокую дыру или замшевый диск каким-либо другим способом, перед проверкой развала схождения поврежденный диск следует либо исправить на специальном станке, либо заменить. Кроме того, давление в шинах проверяется перед процедурой проверки и регулировки. Разница этого давления может нивелировать всю работу и даже привести к обострению возникающих проблем. Кроме того, знающие люди советуют раз в десять тысяч километров пробега менять передние и задние колеса. Эта простая процедура позволяет обеспечить равномерный износ автомобильных шин. Дело в том, что резина на передних колесах всегда прошивается быстрее, чем на задних.
Многое, точность и оперативность регулировки развала концентрации, будет зависеть от калибровки стенда, на котором эта процедура производится. Но это, как уже было сказано, относится к добросовестности специалиста, осуществляющего проверку. Работоспособность инструмента, это в первую очередь забота мастера.
Видео про развал фото
выводы
Проверка и регулировка развала схождения колес, процедура важная и нужная. Особенно это важно в наших условиях, с нашими дорогами и их состоянием. Ввод правильных поворотов Сбор колесного развала позволяет повысить управляемость автомобиля, его устойчивость и устойчивость при движении. Также за счет правильных значений углов установки колес снижается износ ходов авто и расход топлива.
Словосочетание «разваливается» приходилось слышать практически каждому, сегодня оно известно даже тем, кто не водит машину. Но не все знают значение этого термина, когда и как делать расклад, степень его важности и необходимость проведения.
Что такое коллапс?
Развал-схождение — два важных параметра настройки подвески, от правильности настройки которых напрямую зависит контроллер автомобиля. При идеальной регулировке колесные системы находятся в правильном положении при любой скорости движения и при разных углах поворота. Автомобиль отлично ведет себя на дороге, протекторы изнашиваются равномерно, топливо расходуется в стандартном режиме.
Что нужно для работы?
Развал — это угол наклона колес относительно дороги: при верхней части колеса развал считается отрицательным, если он наклонен наружу — положительным. При нулевом смятии износ шин сводится к минимуму, что способствует продлению их эксплуатации.
Схождение — это угол между направлением движения автомобиля и продольной плоскостью вращения дисков. В большинстве случаев колеса автомобиля наклонены немного вперед, в этом случае следует говорить о положительном способе, в противном случае об отрицательном.
Что такое крах расклада?
Регулировка сход-развала повышает устойчивость, улучшает управляемость автомобиля, уменьшает заносы ТС, способствует экономии топлива, снижает износ шин. Автомобиль становится более маневренным, он менее склонен к заносу и опрокидыванию в экстремальных ситуациях, у него хороший риск.
Почему он сбит?
Детали подвески и рулевого управления состоят из тяги и рычагов, соединенных шарнирными элементами. Износ и выход из строя деталей и соединительных элементов приводит к образованию повышенного люфта. В результате изменения расстояния между плоскостями шин управляемость машины снижается, автомобиль лежит во время движения, шины преждевременные. Неисправность может возникнуть и при выходе из строя других деталей.
Как выполнить настройку?
При необходимости ремонта лучше всего обратиться в сервисный центр за профессиональной помощью. Автомобиль должен стоять на ровной поверхности, настройка состоит из двух процедур: регулировки развала и схождения. Технология проведения в разных сервисах может отличаться, иногда мастер предварительно проверяет давление в шинах, данные с установленных на шины шин заносятся в компьютер, результаты заносятся в таблицу. Измерения проводятся с нагрузкой на ствол и без нее, после получения результатов проводится регулировка.
Необходимость
Перед разборкой следует провести небольшую проверку. Если вы поворачиваете руль в любую сторону, а ТС продолжает двигаться по прямой, необходимо немедленно обратиться в сервисный центр. Ремонт необходим и в том случае, если при центральном положении руля автомобиль не движется в плавном направлении. Одним из важных признаков нарушения сход-развала является неравномерный износ шин.
Проверка сбора
Каждый раз при езде на сотке при малейших подозрениях на нарушения опущено, перед тем как делать развал мастера, рекомендуется проверить его самостоятельно. Неточности в работе сход-развала заметны визуально, их можно распознать по определенным отклонениям в поведении автомобиля. Первым признаком является уход автомобиля в сторону с равномерным контролем и без усилий, а также быстрое истирание шин, неравномерный износ протектора.
Как часто делать развал-схождение?
Процедуру рекомендуется проводить через 15-20 тыс. км, примерно раз в полгода. В целях экономии корректировку балла следует проводить после каждой смены шин весной и осенью. Регулировку также следует производить в следующих случаях:
- проведение некоторых видов ремонтных работ, замена расходных материалов;
- нарушение нормальной эксплуатации автомобиля (увод в сторону, смещение руля, задержки в управлении, «плавание» в колее;
- разный радиус поворота вправо/влево, невозврат автомобиля при выходе из поворота.
Что будет, если не делать?
Если развал-схождение делать редко или не делать, транспортабельность автомобиля снижается. Автомобиль может быть неплох в самый неожиданный момент, при движении по сухому покрытию проблем может и не быть, а при попадании на мокрый или обледенелый участок машина может уйти не в ту сторону. Непрерывная езда с нерегулируемым сходом может спровоцировать «необдуманную» подвеску машины, в результате снизится ее устойчивость. Транспортное средство может быть фактором высокого риска для остальной части движения.
Развал автомобиля схождение на фото
Регулировка развала схождения колес своими руками
Углы установки автомобильных колес, известные в быту как развал-схождение, влияют на его управляемость, устойчивость на поворотах и износ шин.
Развал — это угол между вертикалью и плоскостью вращения колеса.
Развал считается отрицательным, если колеса наклонены верхней стороной внутрь, и положительным, если верхней стороной наружу.
В большинстве случаев под развалом колес автомобиля понимают статический развал управляемых колес, указанный при техническом обслуживании автомобиля.
В некоторых автомобилях регулировке подлежит статический развал неуправляемых колес.
Основное назначение статического развала управляемых колес — уменьшить передачу на руль их движения, возникающего при выезде на мелкие неровности покрытия.
Вместо передачи через рулевые трапеции на руль они гасятся за счет эластичности шин.
Кроме того, развал обеспечивает максимальное сцепление шины с поверхностью дороги при движении автомобиля и устойчивость на поворотах, влияя, таким образом, на устойчивость и управляемость, а также влияет на интенсивность и характер износа протектора шины.
С точки зрения кинематики подвеска разваливалась, наряду с углом поперечного наклона оси поворота управляемого колеса влияет на величину радиуса рифучата, но его влияние существенно меньше второго указанного параметра.
В случае автомобиля с подвеской большинства типов, за исключением МакФерсон, развал для передних управляемых колес, как правило, имеет незначительное положительное значение (колеса наклонены наружу) — в пределах от 0′ до 45′ , местами до 2°.
Это его значение позволяет уменьшить усилия на управляемых колесах и уменьшить передачу на рулевое управление рывков, возникающих при движении по неровностям дороги.
Большой отрицательный развал («Колеса Домича») является признаком износа подвески или неправильной ее регулировки и приводит к быстрому износу шин, ухудшению сцепных свойств на ровной дороге и нарушению устойчивости автомобиля.
Однако на автомобилях с подвеской МакФерсон применяется нулевой или малый отрицательный развал, что связано с различием других установочных параметров этой подвески, обусловленным ее конструктивными особенностями.
Также отрицательный развал устанавливается на гоночные автомобили, предназначенные для езды на овальных, на внутренних колесах.
На двухтактных подвесках статический развал, как правило, можно регулировать.
На автомобилях с подвеской МакФерсон уменьшение клиренса простым укорачиванием пружин приведет к изменению всех четырех углов установки колеса, поэтому для изменения клиренса необходимо менять весь узел крепления подвески.
Первоначально статическое обрушение измерялось с помощью водопровода и уровней различных систем, либо оптических датчиков с компьютерной обработкой, либо в настоящее время используются гравитационные датчики наклона.
Стоит отметить, что на практике угол статического развала задается очень грубо (допуск при его установке обычно сопоставим с его значением) и, кроме того, он довольно сильно меняется при выполнении подвески.
Так что на практике его установка в основном влияет на равномерный износ протектора передней шины — неправильно выставленный развал приводит к повышенному износу внутренней или внешней стороны протектора шины. Кроме того, развал должен быть одинаковым с обеих сторон, так как при одностороннем наклоне колес автомобиль начинает «уводить» в сторону при движении по прямой.
На автомобиле с независимой или полунезависимой подвеской развал колеблется в больших пределах при крене автомобиля или изменении загрузки.
Значение развала, возникающего при движении автомобиля, называется динамическим развалом колес.
На большегрузных автомобилях «Татра» с подвеской на качающихся полуосях динамический развал задних колес на ненагруженном автомобиле настолько велик, что автомобиль едет, опираясь только на внешнюю часть шины.
Даже в подвеске с двойными поперечными рычагами, вполне совершенной с точки зрения кинематики, как правило, при максимальном ходе сжатия заданный изначально положительный статический развал сменяется отрицательным динамическим.
Схождение — Угол между направлением движения и плоскостью вращения колеса.
Очень часто говорят о суммарном соединении двух колес на одной оси.
В некоторых автомобилях можно регулировать схождение как передних колес, так и задних.
Назначение схождения заключается в компенсации возникающего при наличии положительного развала (динамической дестабилизации) колес, что значительно снижает износ шин. Оба уголка взаимосвязаны и регулируются исключительно в комплекте.
Выравнивание измеряется в градусах/минутах (знаки ° и ‘) и в миллиметрах.
Схождение в миллиметрах — это расстояние между задними кромками колеса минус расстояние между передними кромками колеса (в справочниках обычно приводятся данные по стандартным колесам, при произвольном диаметре колеса требуется перерасчет). Это определение верно только в случае целых, правильно установленных колес.
В противном случае применяется процедура Ran-Out (RUN OUT), которая вычитает колесо колеса из величины сходимости.
Неправильно отрегулированное схождение является основной (но не единственной) причиной ускоренного износа шин.
Одним из первых признаков неправильно установленного схождения является визг шин в повороте на небольшой скорости. При 3 и более мм шина полностью стирается менее чем за 1000 км.
Иногда вместо сходящихся колес может потребоваться установка их расхождения (например, на задней оси с независимой подвеской колеса).
Кастер — Угол между вертикалью и проекцией оси вращения колеса на продольную плоскость автомобиля.
Продольный наклон обеспечивает самоуправляемость инвалидной коляски за счет скорости автомобиля.
Другими словами: машина сама выходит из поворота; Отпущенный и имеющий свободный ход руль возвращается в положение прямолинейного движения (на ровной дороге, с отрегулированными механизмами).
Это происходит, конечно, при положительном замке.
Например, воронка позволяет ездить на велосипеде, не держась за руль.
На обычных автомобилях Кастр имеет положительное значение (например, 2,35 градуса у Mitsubishi Outlander XL). Спортсмены устанавливают это значение на несколько градусов больше, что делает ход автомобиля стабильным, а также повышает стремление автомобиля к прямолинейному движению. Наоборот, на цирковых велосипедах или на погрузчиках воронка часто равна нулю, так как скорость движения сравнительно невелика, но возможен поворот по меньшему радиусу.
Но машина создана для большей скорости, поэтому требует лучшей управляемости.
Угол пересечения оси наклона колес
Этот угол обеспечивает самоуправляемость управляемых колес за счет автомобиля.
Дело в том, что в момент отклонения колеса от «нейтрали» начинает подниматься передок.
А так как весит много, то при отпускании руля под действием силы тяжести система стремится занять исходное положение, соответствующее движению по прямой.
Верно, что при этой стабилизационной работе должно сохраняться (пусть и небольшое, но нежелательное) положительное плечо качки. Изначально поперечный угол наклона оси поворота был применен инженерами для устранения недостатков подвески автомобиля.
Избавился от таких «болячек» автомобиля, как положительный развал колес и положительное плечо качения.
Во многих современных автомобилях используется подвеска типа «Мак-Ферссон».
Позволяет получить отрицательное или нулевое плечо реки.
Ведь ось вращения колеса состоит из опоры из одного единственного рычага, который легко помещается внутрь колеса. Но эта подвеска не идеальна, так как из-за ее конструкции угол наклона оси поворота практически невозможен.
В повороте он внешнее колесо наклоняет на невыгодный угол (как положительный развал), а внутреннее колесо при этом наклоняется в противоположную сторону.
В результате пятно контакта на внешнем колесе значительно уменьшается.
А так как на внешнее колесо в повороте большая нагрузка, то вся ось сильно проигрывает в сцеплении.
Это, конечно, можно частично компенсировать заклинанием и коллапсом.
Тогда сцепление внешнего колеса будет хорошим, а внутреннее (менее важное) колесо почти исчезнет.
Зачем нужен развал-схождение на машине?
Для человека этот вопрос уже давно управляется этим вопросом.
Так как кто хоть раз в жизни ездил на машине с нормально отрегулированным развалом развала, тот в дальнейшем чувствует машину на дороге и малейшие отклонения поворотов от нормы, ведь удовольствия от вождения уже нет.
Углы установки колес придуманы конструкторами для того, чтобы мы в полной мере чувствовали себя на дороге комфортно и главное — безопасно, чтобы получить ощущение полного контроля над поведением автомобиля.
Автомобиль с нормальным развалом схождения колес имеет:
1. Хорошая курсовая устойчивость (отклонения от прямолинейного движения должны быть минимальными).
2. Легкое обращение.
3. Маневренность.
4. Меньшая склонность к заносу и опрокидыванию в экстремальных ситуациях.
5. Хорошая прокатка.
6. Экономия топлива.
7. Максимальный ресурс шин на износ и тд.
Автомобиль с сильно нарушенным развалом схождения колес, наоборот, в любой момент может «подложить свинью».
Например, при езде по сухому асфальту вроде бы все хорошо, но стоит только вдруг попасть на мокрую или скользкую дорогу, и ваша машина может вдруг «захотеть» ехать туда, куда вам не захочется.
Автомобиль постоянно приходится «подбирать» (подстраивать) на дороге.
При этом становится постоянным фактором риска не только для водителя, но и для окружающих машин и пешеходов.
Вы никогда не задумывались над ставками дорожно-транспортных происшествий, в которых часто звучат фразы, типа: «Я не справился».
В большинстве случаев это следствие неправильно отрегулированной подвески автомобиля.
Совет
При покупке подержанного автомобиля перед совершением сделки рекомендуется проверить геометрию кузова, на момент ухода автомобиля в прошлое внешний вид может быть обманчив.
Машины попадаются из двух частей, перед с одной, зад с другой.
Причина увода автомобиля — неправильная регулировка углов установки колес. Поговорим, что такое коллапс и конвергенция и когда это нужно делать.
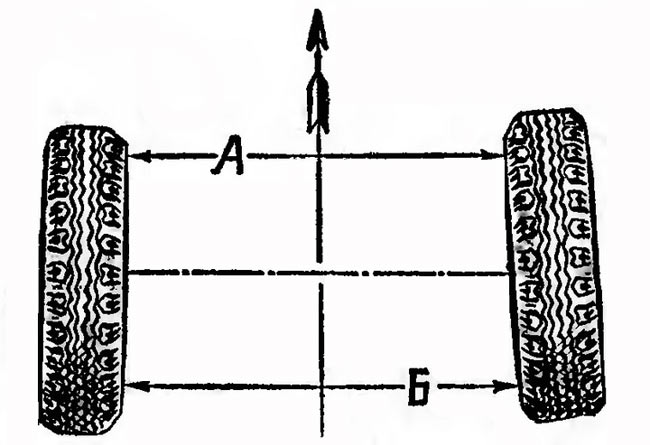
Развал-схождение
Перед автомобилем (вид сверху). Схождение есть разница расстояний А и В. Если а больше b, то схождение считается положительным. Если меньше b — отрицательный. Для переднеприводных автомобилей схождение на передней оси дает ноль или немного отрицательное значение.
Нормальное схождение передних колес является важным фактором устойчивости автомобиля. Определяется путем расчета разницы между краями шин в их заднем и переднем положениях, измеренной на высоте центра колеса между теми же ободьями. Если разница отличается от рекомендованной, требуется корректировка сходимости.
Точная установка схождения производится только на СТО, после проверки надежности крепления рулевого рычага к поворотной рейке, соединения конусов шаровых шарниров рулевого управления, крепления отбойника и маятникового рычага. Если шасси ремонтировалось, необходимо отрегулировать углы подвески.
Схождение регулируется изменением длины руля. Для этого ослабьте хомуты муфты и поверните регулировочные муфты на одинаковую величину в противоположные стороны, изменяя длину боковой нагрузки. По окончании регулировки зажимы оттягивают так, чтобы их концы после не соприкасались.
Разрезное колесо
Это угол между вертикалью и плоскостью вращения машинного колеса. Если верхняя часть колеса наклонена наружу автомобиля, то угол развала положительный, а если внутрь — отрицательный. Визуально видно на фото (вид машины спереди). Большинство автомобилей производители делают с нуля или с небольшим плюсом. Для гоночных машин — поставить отрицательное значение для улучшения управляемости.
Для проверки развала необходимо, чтобы давление воздуха в шинах было в норме, диски не гнулись, свободный ход руля должен соответствовать норме. Перед проверкой убедитесь в исправности рычагов передней подвески, шаровых опор, штоков амортизаторов.
Развал регулируется изменением количества колодок между осью нижнего рычага и поперечиной или вращением эксцентрика на передней стойке. Также существуют для отечественных автомобилей пластины развала задних колес.
Когда делать?
- После замены деталей подвески (амортизаторы, рулевые тяги).
- Шины неравномерно изнашиваются с внутренней или внешней стороны.
- Попали в яму, проехали по границе, после аварии.
- Часто езжу по плохим дорогам, не устраивает управляемость машины.
- Руль стал туго крутиться, чувствуется «осмотр» в сторону при движении прямо.
Как правильно?
Для проверки обрушения можно использовать различное оборудование. От современных 3D-стендов с лазерными датчиками до методов Дедова с зеркалами. Важнее — опыт и квалификация специалиста, чем стоимость оборудования. Например, перед работой необходимо проверить давление в шинах. Если этого не сделать — вся работа будет бесполезной. Также нужно разгрузить машину или использовать столы для частичной загрузки автомобиля.
Далее необходимо устранить биение машины и ошибку устройства. При этом не забывайте проверять состояние подвески. Например, если сайлентблок имеет большой люфт, то контроль углов подвески — бесполезное дело. Затем мастер должен найти данные именно вашего автомобиля (если компьютер подстраивается) и сделать по ним углы. По результатам необходимо дать распечатку показаний до и после.
На современных авто регулировка развала не требуется. Конструкция подвески такова, что исключает изменение углов установки колес в течение определенного периода эксплуатации. Делать это нужно только после ремонта подвески или аварии (сильная посещаемость на границе).
Поддержание правильной установки колес с целью наилучшего движения автомобиля имеет принципиальное значение для сохранения безопасности, удобства управления автомобилем и продления срока службы протектора. Оптимальное расположение колес – особенно передних – является гарантией того, что все четыре колеса совместимы друг с другом и оптимизированы для максимального контакта с поверхностью дороги. В целом регулировка расположения колеса устанавливается по всем трем измерениям, которые в конкретном автомобильном контексте называются 9.0128 обрушение , схождение и ролик . Именно о первых двух параметрах мы поговорим в этой статье, а о Кастере — в следующей.
Развал
Наиболее широко обсуждаемым и часто вызывающим споры, а также важнейшим параметром регулировки колес, от которого зависит управляемость и срок службы шин и некоторых элементов ходовой части, является коллапс, который измеряется в градусах. Развал осуществляется перпендикулярно расположению колес относительно плоскости дороги (см. рисунок справа). Если колесо находится абсолютно перпендикулярно поверхности дороги, то его кривизна будет равна 0 градусов. Развал описывается как отрицательный, когда верхняя часть колеса наклоняется внутрь в дугу автомобиля. Нормальным считается уровень развала +2 градуса (то есть колеса полностью немного отклоняются от автомобиля, если смотреть на машину спереди или сзади). Такое небольшое отклонение от перпендикулярной плоскости необходимо для лучшего сцепления шин автомобиля с дорогой, а также более легкого поворота руля.
Кроме того, углы развала на левом и правом передних колесах должны быть максимально одинаковыми, иначе автомобиль будет тянуть руль в сторону.
Негативный коллапс, однако, становится все более популярным из-за своей визуальной привлекательности. Реальные преимущества отрицательного коллапса видны на характеристиках управляемости. Агрессивный водитель воспользуется такими преимуществами, как улучшенное сцепление при резком повороте с отрицательным развалом. Однако при прямом ускорении отрицательное сложение уменьшит поверхность контакта между шинами и поверхностью дороги.
К сожалению, отрицательный развал порождает так называемую осевую силу — когда обе шины расположены под отрицательным углом, то они как бы толкают друг друга, и хорошо, если обе шины соприкасаются с поверхностью дороги. Но когда одна шина теряет сцепление, другая уже не обременена приложенной к ней силой противовеса, и в результате автомобиль значительно теряет устойчивость. Кроме того, он существенно прошивает и без того дорогие автомобильные покрышки.
Нулевые переменные приведут к более равномерному износу шин в течение длительного времени, но могут снизить производительность при прохождении поворотов. В конечном итоге оптимальный развал в каждом конкретном случае будет зависеть от вашего стиля вождения. И все же для спокойной и стандартной езды указанное выше значение составляет +2 градуса.
Схождение
Пожалуй, проще всего визуализировать концепцию регулировки колес — это схождение. Схождение – это угол расположения колес в горизонтальной плоскости относительно длины автомобиля. То есть если смотреть на машину сверху вниз, то передние кромки колес будут либо немного смотреть внутрь, либо будут параллельны.
Правильное схождение имеет первостепенное значение для равномерного износа и увеличения срока службы шин. Если шины смотрят внутрь или наружу, они будут немного скользить по поверхности дороги и вызывать износ по краям. Однако иногда ресурсом протектора можно пожертвовать ради производительности или стабильности поведения автомобиля на дороге.
Положительный угол схождения возникает, когда оба передних колеса обращены друг к другу. Положительное схождение позволяет обоим колесам постоянно генерировать мощность друг против друга, что снижает вероятность поворота.
Небольшие отрицательные углы часто используются в переднеприводных автомобилях в связи с тем, что их рычаги подвески немного тянут колеса внутрь, так что небольшое отрицательное отклонение схождения компенсирует сопротивление и позволяет выровнять колеса при скорость.
Кроме того, отрицательный угол схождения увеличивает эффективность поворота автомобиля. Когда транспортное средство начинает вращаться, внутреннее колесо будет наклонено более агрессивно, и его радиус вращения будет меньше, чем у внешнего колеса.
Коллапс-схождение — что это? Сделать развал-схождение
Всем автолюбителям хорошо известно, что даже незначительное вмешательство в ходовую часть автомобиля приведет к изменению углов установки колес, а следовательно, и к изменению поведения автомобиля на дороге. Параметры развала-схождения могут зависеть и от других факторов: износа резины, давления в шинах, люфта. Любой автомобиль приходит к такому состоянию, когда возникает необходимость ремонта передней подвески. А если производить самому, то велик риск нарушить такие параметры, как дезинтеграция, конвергенция. К чему может привести такое нарушение? Самые тяжелые последствия.
Определение
Коллапс-конвергенция — что скрывается под этим определением? Это установка правого угла поворота колеса. Для обеспечения хорошей устойчивости и управляемости передние колеса необходимо устанавливать под определенным углом по отношению к подвеске и кузову автомобиля.
Крошащийся
Часто для регулировки подвески используют термин «столкновение-схождение». Что такое коллапс? Это угол между плоскостью, в которой вращается колесо, и вертикалью. Отрицательным считается такой развал, когда колеса верхнего борта наклонены внутрь. Положительный развал — это когда верхняя сторона колес наклонена наружу. Развал обеспечивает правильное положение колеса при работе подвески. С изменением наклона автомобиля меняется и развал. Если развал равен нулю, то шины изнашиваются минимально. Если отрицательный, то улучшается устойчивость автомобиля на поворотах. По размеру правый и левый развал должны быть максимально приближены друг к другу. В противном случае это может привести к уводу автомобиля с прямой траектории хода, а также к одностороннему износу рисунка протектора. Это только одна часть термина «коллапс-конвергенция».
Конвергенция
Что такое конвергенция? Это угол между плоскостью, в которой вращается колесо, и направлением движения. Он обеспечивает правильное положение передних колес автомобиля при разных скоростях и углах поворота. Чаще всего схождение регулируется изменением длины боковых тяг руля.
Конструкция подвески большинства автомобилей позволяет регулировать развал, схождение колес, а также продольный наклон шкворня, являющегося осью вращения управляемого колеса автомобиля.
Кастер
Продольный наклон шкворня или шкворня — это угол между проекцией линии, проходящей через середину шаровых опор, на плоскость, параллельную продольной оси транспорта, и вертикалью. Такой наклон обеспечивает стабилизацию передних колес автомобиля в направлении прямолинейного движения. Его еще называют «кастер». Это очень важно, так как разница наклона для правого и левого колеса, превышающая допустимые значения, может привести к заносу в сторону менее важного колеса.
Разницу в стоимости кастера можно выразить таким параметром, как разница в его наклонах. Результат вычитания из большего значения меньшего колеса не должен быть больше 30 минут.
Продольный уклон облегчает самовыравнивание колес в зависимости от скорости автомобиля. Гонщики устанавливают это значение на пару градусов выше заводских настроек. Это делает ход транспорта более стабильным, а желание двигаться по прямой возрастает.
Характерными признаками отклонения от нормальных значений являются: визг шин при повороте, увод автомобиля при движении в сторону, односторонний износ рисунка протектора, неравномерное усилие при правых и левых поворотах на руль.
Угол движения характеризуется поворотом задней оси по отношению к оси симметрии автомобиля. Этот параметр очень важен и чем ближе его значение к нулю, тем лучше. Если значение положительное, значит, есть наклон вправо, а если отрицательное, то влево. Если есть отклонения больше допустимых значений, нужно срочно вмешиваться и доводить до нормы.
Перед тем, как сделать развал, необходимо убедиться, что давление в шинах нормальное, износ протектора на обоих колесах примерно одинаковый, нет люфта в рулевом управлении и подшипниках, колесные диски не деформированы, нет необходимо отремонтировать подрамник автомобиля.
Рулевое колесо на прямой неровно
Эта проблема может быть вызвана несколькими причинами:
- Увеличен свободный ход.
- Автомобиль имеет поворот заднего моста. То есть нужно держать спину и сворачивать-сходить. Это исправит ситуацию.
- В развале задних колес может быть слишком большая разница.
- Существует разница в давлении задних и передних колес.
- Имеются невидимые дефекты ходовой части, которые не проявлялись до проведения развал-схождения.
Если кроме наклона руля имеет место еще и отклонение транспорта в сторону, необходимо сначала выяснить и устранить причину, вызывающую это отклонение, и только потом установить правильное положение руля .
Машину ведет в сторону, хотя развал
Что это может быть в таком случае?
1. Необходимо проверить действие резины. Для этого передние колеса меняются местами. Если после этого действия отвод меняет направление, то все дело в резине. Вам нужно поменять все колеса по кругу и искать пару, на которой машина будет ехать плавно. После этого выравнивается направление вращения колес. В последнее время такая причина ухода встречается очень часто. И всему виной качество шин.
2. Дисбаланс колес можно увеличить. Колеса скручены.
3. Проведена проверка и такого параметра, как развал-схождение, только на передней оси. Также необходимо проверить задний мост, так как причина неисправности может быть именно в нем.
4. Имеются скрытые нарушения ходовой части автомобиля, не выявленные до регулировки.
Перед регулировкой машину не забирал, но резина быстро изнашивалась, а потом появился увод.
Здесь, как и в предыдущем пункте, причина кроется, скорее всего, в резине. Раньше машина ехала ровно, так как увод, создаваемый резиной, уравновешивался заносом, созданным из-за неправильно выполненной развал-схождения. ВАЗ к этому склонен. После устранения одной причины произошел уход в сторону.
Тугой руль
Причин этой проблемы может быть несколько:
- Неправильная регулировка. Нам нужно снова сделать выравнивание.
- При ремонте установлены очень тугие рулевые тяги или шаровые опоры.
- В шинах слишком низкое давление воздуха.
- Вылет дисков не соответствует рекомендованному производителем.
Какова процедура свертывания-схождения?
У многих возникает вопрос: нужно ли делать разбивку? Для человека, который давно водит машину, ответ на него очевиден. Кто хоть раз ездил на машине с правильно отрегулированными колесами, тот лучше почувствует машину при езде, и даже заметит малейшее отклонение поворотов.
Человек за рулем должен отдыхать и получать удовольствие от процесса вождения. Именно для этого инженеры и придумали углы установки колес. Ведь водителю в дороге должно быть комфортно и максимально безопасно.
Автомобиль, у которого правильно отрегулированы углы установки колес, имеет:
- Хорошую курсовую устойчивость, то есть отклонения от прямолинейного движения минимальны.
- Хорошая маневренность и управляемость, а также комфорт при вождении.
- Меньшая склонность к заносу, а также к опрокидыванию в опасных ситуациях.
- Экономия топлива и минимальный износ шин.
- Хорошее падение.
Автомобиль, который сильно нарушил повороты, наоборот, может подвести водителя в любой момент. Например, при езде по сухому покрытию все может быть в порядке, но как только машина попадет на скользкий или мокрый участок дороги, она может неожиданно пойти не туда, где надо. Приходится постоянно подгонять машину. И тем самым становится опасным не только для водителя, но и для окружающего транспорта, а также пешеходов. Часто неправильная регулировка приводит к печальным последствиям. Поэтому лучше сделать разбивку. ВАЗ самый популярный в России, и все мастера легко настроят. Другие марки также хорошо поддаются правильной регулировке угла наклона колес. Во всех развитых странах это обязательный пункт техосмотра.
Еще один очень важный момент, это то, что при покупке автомобиля с рук рекомендуется проверить его на исправность ходовой части, ведь большинство продаваемых автомобилей в прошлом подвергались авариям. Есть даже образцы, которые собраны из двух разных половинок, и сварены они не лучшим образом.
Когда проверять развал-схождение
1. После ремонта ходовой части автомобиля, когда были заменены какие-либо детали.
2. После любых работ, ведущих к изменению дорожного просвета.
3. Если произошло увод машины в сторону или руль изменил свое положение при прямолинейном движении.
4. Автомобиль слишком туго управляемый или, наоборот, слишком легкий, плохо держит дорогу.
5. Шины очень быстро изнашиваются.
6. Автомобиль уводит в сторону при торможении.
7. Плохое самовращение при выходе из поворота.
8. После процесса обкатки нового автомобиля или в случае покупки подержанного автомобиля.
9. Если пробег после последней регулировки больше 15 тысяч километров.
10. После смены шин по сезонам.
Цена
Стоимость развала-схождения не высока и доступна большинству автовладельцев. Она не должна превышать 700 рублей в том случае, если нет необходимости в сантехнических работах или какой-либо дополнительной наладке. Стоимость развала-схождения в Москве может доходить до 2000 рублей.
Режимы отказа GAN: как их идентифицировать и контролировать
Генеративно-состязательная сеть представляет собой комбинацию двух подсетей, которые конкурируют друг с другом во время обучения, чтобы генерировать реалистичные данные. Генераторная сеть генерирует подлинные искусственные данные, в то время как Дискриминаторная сеть определяет, являются ли данные искусственными или реальными.
Хотя GAN являются мощными моделями, их довольно сложно обучить. Мы обучаем Генератор и Дискриминатор одновременно, за счет друг друга. Это динамическая система, в которой, как только параметры одной модели обновляются, меняется характер задачи оптимизации, и из-за этого достижение сходимости может быть затруднено.
Обучение также может привести к отказу GAN моделировать полное распределение, и это также называется Сбой режима .
В этой статье:
- мы увидим, как обучить стабильную модель GAN
- , а затем поэкспериментируем с процессом обучения, чтобы понять возможные причины сбоев режима.
Я тренировал GAN в течение последних нескольких лет и заметил, что обычные режимы отказа в GAN — Mode Collapse и Convergence Failure , о которых мы поговорим в этой статье.
Пропустите раздел обучения и перейдите к разделу режимов отказа ->
Обучение стабильной сети GAN
Чтобы понять, как может произойти сбой (при обучении GAN), давайте сначала обучим стабильную сеть GAN. Мы будем использовать набор данных MNIST, нашей целью будет создание искусственных рукописных цифр из случайного шума с использованием сети генератора.
Генератор примет на вход случайный шум, а на выходе будут фальшивые рукописные цифры размером 28×28. Дискриминатор будет принимать входные изображения 28 × 28 как от генератора, так и от наземной правды, и попытается правильно их классифицировать.
Я взял скорость обучения 0,0002 для оптимизатора Адама и 0,5 в качестве импульса для оптимизатора Адама.
Давайте посмотрим на код нашей стабильной сети GAN. Во-первых, давайте сделаем необходимый импорт.
импортная горелка импортировать torch.nn как nn импортировать torchvision.transforms как преобразования импортировать torch.
Обратите внимание, что в этом упражнении мы будем использовать PyTorch для обучения нашей модели и панель инструментов neptune.ai для отслеживания экспериментов. Вот ссылка на все мои эксперименты. Я запускал сценарии в colab, и Neptune упростил отслеживание всех экспериментов.
Правильное отслеживание эксперимента в этом случае действительно важно, потому что графики потерь и промежуточные изображения могут очень помочь определить, есть ли режим отказа. В качестве альтернативы вы можете использовать matplotlib, священный, TensorBoard и т. д., в зависимости от вашего варианта использования и удобства.
Сначала мы инициализируем запуск Neptune. Вы можете получить путь к проекту и токен API после создания проекта на панели инструментов Neptune.
запуск = neptune.init( проект="имя проекта", api_token="Ваш токен API", )
Мы сохраняем размер партии 1024 и будем работать в течение 100 эпох. Скрытое измерение инициализируется для генерации случайных данных для ввода генератора. И размер выборки будет использоваться для вывода 64 изображений в каждую эпоху, чтобы мы могли визуализировать качество изображений после каждой эпохи. k — количество шагов, для которых мы собираемся запускать дискриминатор.
размер_пакета = 1024
эпохи = 100
размер_образца = 64
скрытый_дим = 128
к = 1
устройство = torch.device('cuda', если torch.cuda.is_available() иначе 'процессор')
преобразование = преобразование.Составить([
преобразовывает.ToTensor(),
преобразовывает. Нормализовать ((0,5,), (0,5,)),
])
Теперь мы загружаем данные MNIST и создаем объект Dataloader.
train_data = наборы данных.MNIST( корень='../ввод/данные', поезд = правда, скачать = Верно, трансформировать = трансформировать ) train_loader = DataLoader (train_data, batch_size=batch_size, shuffle=True)
Наконец, мы определяем некоторые гиперпараметры для обучения и передаем их на панель инструментов Neptune с помощью объекта запуска.
параметров = {"learning_rate": 0,0002,
"оптимизатор": "Адам",
"оптимизатор_бетас": (0,5, 0,999),
"латентный_дим": латентный_дим}
run["parameters"] = params Здесь мы определяем сети генератора и дискриминатора.
Генераторная сеть
- Генераторная модель использует в качестве входных данных скрытое пространство, которое является случайным шумом.
- В первом слое мы меняем скрытое пространство (размерность 128) на функциональное пространство из 128 каналов и каждого канала высотой и шириной 7×7.
- Следуя двум слоям деконволюции, увеличьте высоту и ширину нашего пространства признаков.
- Затем следует слой свертки с активацией tanh для создания изображения с одним каналом и высотой и шириной 28×28.
Генератор класса (nn.Module):
def __init__(я, скрытое_пространство):
супер(Генератор, сам).__init__()
self.latent_space = скрытое_пространство
self.fcn = nn.Sequential(
nn. Linear(in_features=self.latent_space, out_features=128*7*7),
nn.LeakyReLU(0.2),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d (in_channels = 128, out_channels = 128, kernel_size = (4, 4), stride = (2, 2), padding = (1, 1)),
nn.LeakyReLU(0.2),
nn.Conv2d (in_channels = 128, out_channels = 1, kernel_size = (3, 3), padding = (1, 1)),
nn.Tanh()
)
защита вперед (я, х):
х = self.fcn(x)
х = х.вид (-1, 128, 7, 7)
х = саморазвитие (х)
возврат х См. также
➡️ 6 архитектур GAN, которые вы действительно должны знать
Сеть дискриминатора
- Наша сеть дискриминатора состоит из двух сверточных слоев для генерации признаков из изображения, поступающего от генератора, и реальных изображений.
- За ним следует слой классификатора, который классифицирует, является ли изображение предсказанным дискриминатором реальным или поддельным.
Дискриминатор класса (nn.Module):
защита __init__(сам):
супер(Дискриминатор, я).__init__()
self.conv = nn.Sequential(
nn.Conv2d (in_channels = 1, out_channels = 64, kernel_size = (4, 4), шаг = (2, 2), заполнение = (1, 1)),
nn.LeakyReLU(0.2),
nn.Conv2d (in_channels = 64, out_channels = 64, kernel_size = (4, 4), шаг = (2, 2), заполнение = (1, 1)),
nn.LeakyReLU(0.2)
)
self.classifier = nn.Sequential(
nn.Linear(in_features=3136, out_features=1),
nn.Сигмоид()
)
защита вперед (я, х):
х = самоутверждение (х)
х = х.вид (х.размер (0), -1)
х = самоклассификатор (х)
возврат х Теперь мы инициализируем сеть генератора и дискриминатора, а также оптимизаторы и функцию потерь.
И у нас есть несколько вспомогательных функций для создания меток для поддельных и реальных изображений (где size — это размер пакета) и функция create_noise для ввода генератора.
генератор = Генератор (latent_dim).to (устройство) дискриминатор = дискриминатор().к(устройство) optim_g = optim.Adam (параметры генератора (), lr = 0,0002, бета = (0,5, 0,999)) optim_d = optim.Adam (дискриминатор. параметры (), lr = 0,0002, бета = (0,5, 0,999)) критерий = nn.BCELoss() def label_real (размер): labels = torch.ones(размер, 1) вернуть labels.to(устройство) определение label_fake (размер): labels = torch.zeros(размер, 1) вернуть labels.to(устройство) def create_noise (sample_size, hidden_dim): return torch.randn(sample_size, hidden_dim).to(device)
Функция обучения генератора
Теперь мы обучим генератор:
- Генератор принимает случайный шум и выдает поддельные изображения.
- Эти поддельные изображения затем отправляются в дискриминатор, и теперь мы минимизируем потери между реальной меткой и предсказанием дискриминатора поддельного изображения.
- С помощью этой функции мы будем наблюдать потери генератора.
def train_generator (оптимизатор, data_fake): b_size = data_fake.size (0) реальная_метка = реальная_метка(b_size) оптимизатор.zero_grad() вывод = дискриминатор (data_fake) потеря = критерий (выход, реальная_метка) потеря.назад() оптимизатор.шаг() обратная потеря
Функция обучения дискриминатора
Мы создаем функцию train_discriminator:
- Эта сеть, как мы знаем, получает входные данные от наземной истины (т.е. реальных изображений) и генераторной сети (т.е. поддельных изображений) во время обучения.
- Одно за другим мы передаем поддельное и реальное изображение, вычисляем потери и обратное распространение. Мы будем наблюдать две потери дискриминатора; потери на реальных изображениях (loss_real) и потери на поддельных изображениях (loss_fake).
def train_distributor (оптимизатор, data_real, data_fake): b_size = data_real.size (0) реальная_метка = реальная_метка(b_size) поддельная_метка = метка_поддельная (b_size) оптимизатор.
Обучение модели GAN
Теперь, когда у нас есть все функции, давайте обучим нашу модель и посмотрим на наблюдения, чтобы определить, стабильно ли обучение или нет.
- Шум в первой строке будет использоваться для вывода промежуточных изображений после каждой эпохи. Мы сохраняем шум одинаковым, чтобы мы могли сравнивать изображения в разные эпохи.
- Теперь для каждой эпохи мы обучаем дискриминатор k раз (один раз в данном случае, поскольку k=1), за каждый раз обучается генератор.
- Все потери регистрируются и отправляются на панель управления Neptune для построения графика. Нам не нужно добавлять их в список, используя панель инструментов Neptune, мы можем строить графики потерь на лету. Он также будет записывать потери на каждом этапе в файле .csv.
- Я сохранил сгенерированные изображения после каждой эпохи в метаданных Neptune, используя функцию [dot]upload.
шум = создать_шум (размер выборки, скрытый_тусклый)
генератор.поезд()
дискриминатор.train()
для эпохи в диапазоне (эпохи):
потеря_г = 0,0
loss_d_real = 0,0
loss_d_fake = 0,0
# подготовка
для bi данные в tqdm(enumerate(train_loader), total=int(len(train_data)/train_loader.batch_size)):
изображение, _ = данные
изображение = изображение.на(устройство)
b_size = длина (изображение)
для шага в диапазоне (k):
data_fake = генератор (создать_шум (b_size, скрытый_дим)). отсоединить ()
data_real = изображение
loss_d_fake_real = train_distributor (optim_d, data_real, data_fake)
loss_d_real += loss_d_fake_real[0]
loss_d_fake += loss_d_fake_real[1]
data_fake = генератор (создать_шум (b_size, скрытый_дим))
loss_g += train_generator(optim_g, data_fake)
# вывод и наблюдения
сгенерированный_img = генератор (шум). процессор (). отсоединить ()
сгенерированный_img = make_grid (сгенерированный_img)
сгенерированный_img = np.moveaxis (сгенерированный_img.numpy (), 0, -1)
run[f'generated_img/{эпоха}'].upload(File.as_image(generated_img))
epoch_loss_g = loss_g / би
epoch_loss_d_real = loss_d_real/bi
epoch_loss_d_fake = loss_d_fake/bi
run["train/loss_generator"].log(epoch_loss_g)
run["поезд/убыток_дискриминатор_реальный"].log(epoch_loss_d_real)
run["поезд/потеря_дискриминатора_фальшивка"].log(epoch_loss_d_fake)
print(f"Эпоха {эпоха} из {эпох}")
print(f"Потеря генератора: {epoch_loss_g:.8f}, Ложная потеря дискриминатора: {epoch_loss_d_fake:.8f}, Реальная потеря дискриминатора: {epoch_loss_d_real:.8f}") Посмотрим на промежуточные изображения.
Эпоха 10
Рис. 1 – Цифры, сгенерированные стабильной GAN на 10-й эпохе | Источник: АвторЭто 64 цифры, сгенерированные в эпоху 10.
Эпоха 100
Рис. 2 – Цифры, сгенерированные из стабильной GAN в эпоху 100 | Источник: Автор Они созданы с использованием того же шума в эпоху 100. Они выглядят намного лучше, чем изображения в эпоху 10, здесь мы действительно можем идентифицировать разные цифры. Мы можем обучаться еще большему количеству эпох или настраивать гиперпараметры для лучшего качества изображений.
Графики убытков
Вы можете легко перейти в «Добавить новую панель мониторинга» на панели мониторинга Neptune и объединить различные графики потерь в один.
Рис. 3 – График потерь, три линии показывают потери для генератора, поддельные изображения на дискриминаторе и реальные изображения на дискриминаторе | Источник На рис. 3 вы можете наблюдать стабилизацию потерь после эпохи 40. Потери дискриминатора для реального и поддельного изображений остаются около 0,6, тогда как для генератора они составляют около 0,8. Приведенный выше график является ожидаемым графиком для стабильной тренировки. Мы можем рассматривать это как базовый уровень и экспериментировать с изменением k (шаги обучения для дискриминатора), увеличением количества эпох и т. д.
Теперь, когда мы построили стабильную модель GAN, давайте посмотрим на режимы отказа.
Связанные
➡️ Понимание функций потери GAN
Режимы отказа GAN
В последние годы мы наблюдаем быстрый рост приложений GAN, будь то увеличение разрешения изображений, генерация условного или реального как синтетические данные.
Неудача в обучении является серьезной проблемой для таких приложений.
Как определить режимы отказа GAN? Как мы узнаем, есть ли режим отказа:
- В идеале генератор должен выдавать разнообразные данные. Если он производит один вид или аналогичный набор выходных данных, это Mode Collapse .
- Когда генерируются визуально неправильные наборы данных, это может быть случаем Ошибка конвергенции .
Что вызывает сбой режима в GAN? Причины режимов отказа:
- Невозможность найти конвергенцию для сетей.
- Генератор может найти определенный тип данных, который может легко обмануть дискриминатор. Он будет снова и снова генерировать одни и те же данные, предполагая, что цель достигнута. Вся система может переоптимизировать этот единственный тип вывода.
Проблема с определением сбоя режима и других режимов отказа заключается в том, что мы не можем полагаться на качественный анализ (например, на просмотр данных вручную). Этот метод может дать сбой, если имеется огромное количество данных или если проблема действительно сложна (мы не всегда будем генерировать цифры).
Оценка режимов отказа
В этом разделе мы попытаемся понять, как определить, имеет ли место сбой режима или сбой конвергенции. Мы увидим три метода оценки. Один из них мы уже обсуждали в предыдущем разделе.
Глядя на промежуточные изображения
Давайте посмотрим несколько примеров, где по промежуточным изображениям можно оценить режим коллапса и конвергенции. На рис. 4 мы видим изображения действительно плохого качества, а на рис. 5 мы видим тот же набор сгенерированных изображений.
Хотя на рис. 4 показан пример сбоя сходимости, на рис. 5 показан сбой режима. Вы можете получить представление о том, как работает ваша модель, просмотрев изображения вручную. Но когда сложность проблемы высока или данные для обучения слишком велики, вы не сможете идентифицировать коллапс режима.
Давайте рассмотрим несколько лучших методов.
По графикам потерь
Мы можем многое узнать о том, что происходит, посмотрев на графики потерь. Например, на рис. 3 вы можете заметить, что потери насыщаются после определенного момента, демонстрируя ожидаемое поведение. Теперь давайте посмотрим на этот график потерь на рис. 6, где я уменьшил скрытое измерение, поэтому поведение неустойчиво.
На рис. 6 видно, что потери генератора колеблются между 1 и 1,2. Хотя потери дискриминатора для поддельных и реальных изображений также колеблются около 0,6, потери несколько больше, чем мы заметили в стабильной версии.
Я бы посоветовал, даже если график имеет высокую дисперсию, это нормально. Вы можете увеличить количество эпох и подождать еще некоторое время, пока оно не станет стабильным, и, самое главное, продолжать проверять сгенерированные промежуточные изображения.
Если график потерь падает до нуля в начальные эпохи как для генератора, так и для дискриминатора, то это тоже проблема. Это означает, что генератор нашел набор поддельных изображений, которые действительно легко идентифицировать дискриминатору.
Количество статистически различных интервалов (показатель NDB)
В отличие от двух вышеупомянутых качественных методов, оценка NDB является количественным методом. Таким образом, вместо того, чтобы просматривать изображения и графики потерь и что-то упускать или делать неправильную интерпретацию, оценка NDB может определить, есть ли сбой режима.
Давайте разберемся, как работает оценка NDB:
- У нас есть два набора, обучающий набор (на котором обучается модель) и тестовый набор (поддельные изображения, сгенерированные генератором на случайном шуме после обучения).
- Теперь разделите обучающую выборку на K кластеров, используя кластеризацию K-средних. Это будут наши K разных бункеров.
- Теперь распределите тестовые данные по этим K интервалам на основе евклидова расстояния между точками тестовых данных и центроидами K кластеров.
- Теперь проведите тест с двумя выборками между обучающей и тестовой выборками для каждого бина и рассчитайте Z-показатель. Если Z-оценка меньше порогового значения (в статье используется 0,05), пометьте ячейку как статистически отличающуюся.
- Подсчитайте количество статистически различных бинов и разделите их на K.
- Полученное значение будет находиться в диапазоне от 0 до 1.
Большое количество статистически различных бинов означает, что значение ближе к 1, что означает коллапс высокой моды, что означает плохой модель. Тем не менее, оценка NDB, приближающаяся к 0, означает меньшее коллапс режима или его отсутствие.
Метод оценки NDB взят из статьи О GAN и GMM.
Рис. 7 — (a) Вверху слева — изображение из набора обучающих данных (b) Внизу слева — изображение из набора тестовых данных и показано перекрытие (c) Гистограмма, показывающая бины для обучающего и тестового набора | ИсточникОчень хорошо реализованный код для вычисления NDB можно найти в этой записной книжке совместной работы Кевина Шена.
Решение режимов отказа
Теперь, когда у нас есть понимание того, как выявлять проблемы при обучении GAN, мы рассмотрим некоторые решения и эмпирические правила для их решения. Некоторые из них будут базовыми настройками гиперпараметров. Мы обсудим некоторые алгоритмы, если вы хотите сделать все возможное, чтобы стабилизировать свои GAN.
Функции затрат
Есть документы, в которых говорится, что ни одна функция потерь не превосходит других. Я бы посоветовал вам начать с более простых функций потерь, таких как мы используем бинарную кросс-энтропию, и подняться оттуда.
Теперь нет необходимости использовать определенные функции потерь с определенными архитектурами GAN. Но для написания этих статей было проведено много исследований, многие из которых все еще активны. Таким образом, было бы хорошей практикой использовать эти функции потерь на рис. 8, которые могут помочь вам предотвратить как коллапс моды, так и конвергенцию.
Рис. 8 – Архитектура GAN и соответствующие функции потерь, использованные в статьях | Источник Поэкспериментируйте с различными функциями потерь и обратите внимание, что ваша функция потерь может дать сбой из-за неправильной настройки гиперпараметров, например слишком агрессивного оптимизатора или большой скорости обучения. Мы поговорим об этих проблемах позже.
Скрытое пространство
Скрытое пространство — это место, откуда берется входной сигнал для генератора (случайный шум). Теперь, если вы ограничите скрытое пространство, оно будет производить больше выходных данных того же типа, что видно из рис. 9. Вы также можете посмотреть на соответствующий график потерь на рис. 6.
Рис. пространство 2 | Источник: АвторНа рис. 9 вы видите столько одинаковых восьмерок и семерок? Отсюда и коллапс режима.
Рис. 10. Здесь я указал скрытое пространство как 1, пробежал 200 эпох.Мы видим постоянно увеличивающиеся потери генератора и колебания во всех потерях | Источник Рис. 11 – Подучасток, соответствующий рис. 10, где скрытое пространство равно 1.
Эти цифры генерируются на 200-й эпохе | Источник: Автор
Обратите внимание, что при обучении сети GAN очень важно предоставить достаточное количество скрытого пространства, чтобы генератор мог создавать различные функции.
Скорость обучения
Одна из наиболее распространенных проблем, с которыми я столкнулся при обучении GAN, — это высокая скорость обучения. Это приводит либо к коллапсу мод, либо к неконвергенции. Очень важно, чтобы вы поддерживали скорость обучения на низком уровне, всего 0,0002 или даже ниже.
Рис. 12 – Значения потерь при скорости обучения 0,2 | Источник Рис. 13 — Сгенерированные изображения на 100-й эпохе со скоростью обучения 0,2 | Источник: АвторИз графика потерь на рис. 12 ясно видно, что дискриминатор идентифицирует все изображения как реальные. Вот почему потери для поддельных изображений высоки, а для реальных изображений нет. Теперь генератор предполагает, что все созданные им изображения обманывают дискриминатор. Проблема здесь в том, что дискриминатор даже немного не обучается из-за такой высокой скорости обучения.
Чем выше размер пакета, тем выше может быть значение скорости обучения, но всегда старайтесь быть на более безопасной стороне.
Оптимизатор
Агрессивный модификатор — плохая новость для обучения GAN. Это приводит к невозможности найти равновесие между потерями генератора и потерями дискриминатора и, следовательно, сбоем сходимости.
Рис. 14 – График потерь со значениями по умолчанию для Adam Optimizer (бета 0,9 и 0,999) | ИсточникВ Adam Optimizer бета — это гиперпараметры, используемые для вычисления скользящего среднего значения градиента и его квадрата. Мы изначально (в стабильном обучении) использовали значение 0,5 для бета1. Меняем на 0.9(значение по умолчанию) увеличивает агрессивность оптимизатора.
На рис. 14 дискриминатор работает хорошо. Поскольку потери генератора увеличиваются, мы можем сказать, что он создает такие плохие изображения, что дискриминатору очень легко классифицировать их как поддельные. График потерь не достигает равновесия.
Сопоставление признаков
Сопоставление признаков предлагает новую целевую функцию, в которой мы не используем напрямую выходные данные дискриминатора. Генератор обучен таким образом, что ожидается, что выходные данные генератора будут соответствовать значениям реальных изображений на промежуточных признаках дискриминатора.
Для реального изображения и фальшивого изображения векторы признаков (f(x) на рис. 15) вычисляются на промежуточном слое в мини-пакетах, и измеряется расстояние L2 по средним значениям этих векторов признаков.
Имеет смысл сопоставлять сгенерированные данные со статистикой реальных данных. В случае, если оптимизатор становится слишком жадным в поисках наилучшей генерации данных и никогда не достигает сходимости, сопоставление признаков может быть полезным.
Историческое усреднение
Мы сохраняем скользящее среднее значение параметров (θ) предыдущего t моделей. Теперь мы штрафуем модель, добавляя стоимость L2 к функции стоимости, используя предыдущие параметры.
Рис. 16 – Стоимость L2 | Источник Здесь θ[i] — значение параметра на i -м -м прогоне.
При работе с невыпуклыми целевыми функциями историческое усреднение может помочь сходимости модели.
Заключение
- Теперь мы понимаем важность отслеживания экспериментов при обучении GAN.
- Важно понимать графики потерь и внимательно наблюдать за генерируемыми промежуточными данными.
- Гиперпараметры, такие как скорость обучения, параметры оптимизатора, скрытое пространство и т. д., могут испортить вашу модель, если они не настроены должным образом.
- С увеличением количества моделей GAN за последние несколько лет все больше и больше исследований проводится в области стабилизации обучения GAN. Есть гораздо больше методов, полезных для конкретных случаев использования.
Читать далее
- https://arxiv.org/pdf/1606.03498v1.pdf
- https://towardsdatascience.com/10-lessons-i-learned-training-generative-adversarial-networks-gans-for-a-year-c
59628
- https://towardsdatascience.com/gan- way-to-improve-gan-performance-acf37f9f59b
- https://arxiv. org/pdf/1805.12462.pdf
ЧИТАТЬ СЛЕДУЮЩИЙ
Полное руководство по оценке и выбору моделей в машинном обучении 9
10 минут чтения | Автор Самадрита Гош | Обновлено 16 июля 2021 г.
На высоком уровне машинное обучение представляет собой союз статистики и вычислений. Суть машинного обучения вращается вокруг концепции алгоритмов или моделей, которые на самом деле являются статистическими оценками на стероидах.
Однако любая модель имеет ряд ограничений в зависимости от распределения данных. Ни один из них не может быть абсолютно точным, так как это просто оценок (даже если на стероидах) . Эти ограничения широко известны под названием 9.0396 смещение и дисперсия .
Модель с высоким смещением будет чрезмерно упрощать, не уделяя особого внимания точкам обучения (например, в линейной регрессии, независимо от распределения данных, модель всегда будет предполагать линейную зависимость).
Модель с высокой дисперсией ограничится обучающими данными, не обобщая тестовые точки, которых она не видела раньше (например, случайный лес с max_depth = None).
Проблема возникает, когда ограничения незначительны, например, когда нам приходится выбирать между алгоритмом случайного леса и алгоритмом повышения градиента или между двумя вариантами одного и того же алгоритма дерева решений. Оба будут иметь тенденцию к высокой дисперсии и низкому смещению.
Здесь в игру вступают выбор и оценка модели!
В этой статье мы поговорим о:
- Что такое выбор модели и оценка модели?
- Эффективные методы выбора модели (повторная выборка и вероятностные подходы)
- Популярные методы оценки модели
- Важные недостатки модели машинного обучения
Читать далее ->
Как определить и диагностировать режимы отказа GAN
Автор Джейсон Браунли, , 8 июля 2019 г. , , Генеративно-состязательные сети,
Последнее обновление: 21 января 2021 г.
Как идентифицировать нестабильные модели при обучении генеративно-состязательных сетей.
GAN сложно обучать.
Причина, по которой их трудно обучать, заключается в том, что и модель генератора, и модель дискриминатора обучаются одновременно в игре с нулевой суммой. Это означает, что улучшения одной модели происходят за счет другой модели.
Цель обучения двух моделей состоит в том, чтобы найти точку равновесия между двумя конкурирующими задачами.
Это также означает, что каждый раз, когда обновляются параметры одной из моделей, меняется характер решаемой задачи оптимизации. Это приводит к созданию динамической системы. С точки зрения нейронных сетей, техническая проблема одновременного обучения двух конкурирующих нейронных сетей заключается в том, что они могут не сойтись.
Важно развить интуицию как для нормальной сходимости модели GAN, так и для необычной сходимости моделей GAN, иногда называемой режимами отказа.
В этом руководстве мы сначала разработаем стабильную модель GAN для простой задачи создания изображения, чтобы установить, как выглядит нормальная конвергенция и чего ожидать в более общем плане.
Затем мы по-разному нарушим модели GAN и изучим ряд режимов отказа, с которыми вы можете столкнуться при обучении моделей GAN. Эти сценарии помогут вам развить интуицию в отношении того, что следует искать или ожидать, когда модель GAN не может обучаться, а также идеи о том, что вы можете с этим поделать.
После прохождения этого урока вы будете знать:
- Как определить стабильный процесс обучения GAN по потерям генератора и дискриминатора с течением времени.
- Как определить сбой режима путем просмотра кривых обучения и сгенерированных изображений.
- Как определить сбой сходимости путем просмотра кривых обучения потерь генератора и дискриминатора с течением времени.
Начните свой проект с моей новой книги Генеративно-состязательные сети с Python, включая пошаговые руководства и файлы исходного кода Python для всех примеров.
Начнем.
- Обновлено в августе 2020 г. : исправлена метка на линейном графике.
- Обновлено, январь 2021 г. : обновлено, чтобы замораживание слоев работало с пакетной нормой.
- Обновлено в январе 2021 г. : Упрощенная архитектура модели, чтобы гарантировать, что мы видим сбои.
Практическое руководство по режимам отказа генеративно-состязательной сети
Фото Джейсона Хивнера, некоторые права защищены.
Обзор учебника
Это руководство разделено на три части; они:
- Как определить стабильную генеративно-состязательную сеть
- Как определить сбой режима в генеративно-состязательной сети
- Как определить сбой конвергенции в генеративно-состязательной сети
Как обучить стабильную генеративно-состязательную сеть
В этом разделе мы обучим стабильную GAN генерировать изображения рукописной цифры.
В частности, мы будем использовать цифру «8» из набора рукописных цифр MNIST.
Результаты этой модели позволят установить как стабильную GAN, которую можно использовать для последующих экспериментов, так и профиль того, как выглядят сгенерированные изображения и кривые обучения для стабильного процесса обучения GAN.
Первым шагом является определение моделей.
Модель дискриминатора принимает в качестве входных данных одно изображение в градациях серого 28×28 и выводит двоичный прогноз того, является ли изображение реальным ( класс=1 ) или подделка ( класс=0 ). Он реализован как скромная сверточная нейронная сеть с использованием лучших практик проектирования GAN, таких как использование функции активации LeakyReLU с наклоном 0,2, шагом 2 × 2 для понижения дискретизации и адамовой версией стохастического градиентного спуска со скоростью обучения 0,0002. и импульс 0,5
Приведенная ниже функция Define_DISCINTOR() реализует это, определяя и компилируя модель дискриминатора и возвращая ее. Входная форма изображения параметризована как аргумент функции по умолчанию, чтобы сделать его понятным.
# определить автономную модель дискриминатора def определить_дискриминатор (in_shape = (28,28,1)): # инициализация веса инициализация = случайный нормальный (стандартное отклонение = 0,02) # определить модель модель = Последовательный() # понизить разрешение до 14×14 model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init, input_shape=in_shape)) model.add (LeakyReLU (альфа = 0,2)) # понизить разрешение до 7×7 model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add (LeakyReLU (альфа = 0,2)) # классификатор model.add(Свести()) model.add (плотный (1, активация = ‘сигмоид’)) # скомпилировать модель opt = Адам (lr = 0,0002, beta_1 = 0,5) model.compile (потеря = ‘binary_crossentropy’, оптимизатор = опция, метрики = [‘точность’]) вернуть модель
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 9000. 15 9000 3 9000 2 9000. 15 9000 3 9000 2 9000 3 9000 3 9000 214 9000 3 18 19 | # определить автономную модель дискриминатора def define_compiler(in_shape=(28,28,1)): # инициализация веса init = RandomNormal(stddev=0.02) # определение модели model = Sequential() # понижение разрешения до 14×14 model.add(Conv2D(64, (4,4), strides=(2,2) ), padding=’same’, kernel_initializer=init, input_shape=in_shape)) model.add(LeakyReLU(alpha=0.2)) # понижение разрешения до 7×7 model.add(Conv2D(64, (4,4) ), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2)) # классификатор model.add(Flatten()) model.add(Dense(1, активация=’сигмовидная’)) # скомпилировать модель opt = Adam(lr=0.0002, beta_1=0.5) модель. модель возврата |
Модель генератора принимает в качестве входных данных точку в скрытом пространстве и выводит одно изображение в градациях серого 28×28. Это достигается за счет использования полносвязного слоя для интерпретации точки в скрытом пространстве и обеспечения достаточного количества активаций, которые могут быть преобразованы во множество копий (в данном случае 128) версии выходного изображения с низким разрешением (например, 7×7). ). Затем это дважды подвергается повышающей дискретизации, удваивая размер и увеличивая в четыре раза площадь активаций каждый раз с использованием транспонированных сверточных слоев. В модели используются передовые методы, такие как активация LeakyReLU, размер ядра, зависящий от размера шага, и функция активации гиперболического тангенса (tanh) в выходном слое.
Хотите разработать GAN с нуля?
Пройдите мой бесплатный 7-дневный экспресс-курс по электронной почте прямо сейчас (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получить бесплатную электронную версию курса в формате PDF.
Функция define_generator() ниже определяет модель генератора, но намеренно не компилирует ее, поскольку она не обучается напрямую, а затем возвращает модель. Размер скрытого пространства параметризуется как аргумент функции.
# определить автономную модель генератора
def определить_генератор (скрытый_дим):
# инициализация веса
инициализация = случайный нормальный (стандартное отклонение = 0,02)
# определить модель
модель = Последовательный()
# основа для изображения 7×7
n_узлов = 128 * 7 * 7
model.add(Dense(n_nodes, kernel_initializer=init, input_dim=latent_dim))
model.add (LeakyReLU (альфа = 0,2))
model.add(Изменить форму((7, 7, 128)))
# повысить разрешение до 14×14
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model.add (LeakyReLU (альфа = 0,2))
# повысить разрешение до 28×28
model. add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model.add (LeakyReLU (альфа = 0,2))
# вывод 28x28x1
model.add (Conv2D (1, (7,7), активация = ‘tanh’, заполнение = ‘то же’, kernel_initializer = init))
вернуть модель
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 9000 2 14 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 | # определение модели автономного генератора def define_generator(latent_dim): # инициализация веса init = RandomNormal(stddev=0.02) # определение модели model = Sequential() # основа для изображения 7×7 n_nodes = 128 * 7 * 7 model. init, input_dim=latent_dim)) model. model.add(Reshape((7, 7, 128))) # повысить разрешение до 14×14 model.add(Conv2DTranspose (128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2)) # повысить разрешение до 28×28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer= init)) model.add(LeakyReLU(alpha=0.2)) # output 28x28x1 model.add(Conv2D(1, (7,7), активация=’tanh’, padding=’same’, kernel_initializer =init)) вернуть модель |
Затем можно определить модель GAN, которая объединяет модель генератора и модель дискриминатора в одну большую модель. Эта более крупная модель будет использоваться для обучения весов модели в генераторе с использованием выходных данных и ошибки, рассчитанных моделью дискриминатора. Модель дискриминатора обучается отдельно, и поэтому веса модели помечаются как не подлежащие обучению в этой более крупной модели GAN, чтобы гарантировать, что обновляются только веса модели генератора. Это изменение в обучаемости весов дискриминатора влияет только при обучении комбинированной модели GAN, а не при обучении отдельного дискриминатора.
Эта более крупная модель GAN принимает в качестве входных данных точку в скрытом пространстве, использует модель генератора для создания изображения, которое подается в качестве входных данных для модели дискриминатора, а затем выводится или классифицируется как реальное или поддельное.
Приведенная ниже функция define_gan() реализует это, используя в качестве входных данных уже определенные модели генератора и дискриминатора.
# определить комбинированную модель генератора и дискриминатора для обновления генератора
def define_gan (генератор, дискриминатор):
# делаем веса в дискриминаторе не обучаемыми
дискриминатор.trainable = Ложь
# соедините их
модель = Последовательный()
# добавляем генератор
model.add(генератор)
# добавляем дискриминатор
model.add(дискриминатор)
# скомпилировать модель
opt = Адам (lr = 0,0002, beta_1 = 0,5)
model. compile (потеря = ‘binary_crossentropy’, оптимизатор = опция)
вернуть модель
1 2 3 4 5 6 7 8 10 110003 12 13 14 | # определить комбинированную модель генератора и дискриминатора для обновления генератора0003 # соединить их model = Sequential() # добавить генератор model.add(generator) # добавить дискриминатор model.add(дискриминатор) # скомпилировать модель 3 lr=0,0002, beta_1=0,5)model.compile(loss=’binary_crossentropy’, optimizer=opt) возвращаемая модель |
Теперь, когда мы определили модель GAN, нам нужно ее обучить. Но прежде чем мы сможем обучить модель, нам потребуются входные данные.
Первым шагом является загрузка и масштабирование набора данных MNIST. Весь набор данных загружается через вызов функции load_data() Keras, затем выбирается подмножество изображений (около 5000), принадлежащих к классу 8, например. представляют собой рукописное изображение числа восемь. Затем значения пикселей должны быть масштабированы в диапазоне [-1,1], чтобы соответствовать выходным данным модели генератора.
Функция load_real_samples() ниже реализует это, возвращая загруженное и масштабированное подмножество набора обучающих данных MNIST, готовое к моделированию.
# загрузить изображения mnist защита load_real_samples(): # загрузить набор данных (поездX, обучение), (_, _) = load_data() # расширить до 3D, например. добавить каналы X = expand_dims (trainX, ось = -1) # выбрать все примеры для данного класса selected_ix = обучаемый == 8 Х = Х[выбрано_ix] # преобразовать из целых чисел в числа с плавающей запятой X = X.astype(‘float32’) # шкала от [0,255] до [-1,1] Х = (Х — 127,5) / 127,5 возврат Х
1 2 3 4 5 6 7 8 10 110003 12 13 14 | # загрузить изображения mnist def load_real_samples(): # загрузить набор данных (trainX, trainy), (_, _) = load_data() # расширить до 3d, например. X = expand_dims(trainX, axis=-1) # выбрать все примеры для данного класса selected_ix = trainy == 8 X = X[selected_ix] # преобразование из целых чисел в числа с плавающей запятой X = X.astype(‘float32’) # масштабирование от [0,255] до [-1,1 ] X = (X — 127,5) / 127,5 возврат X |
Нам потребуется одна (или половина) партия реальных изображений из набора данных при каждом обновлении модели GAN. Простой способ добиться этого — каждый раз выбирать случайную выборку изображений из набора данных.
9Функция 0396 generate_real_samples() ниже реализует это, принимая подготовленный набор данных в качестве аргумента, выбирая и возвращая случайную выборку изображений лиц и соответствующую им метку класса для дискриминатора, в частности class=1, указывающую, что они являются реальными изображениями.
# выбрать реальные образцы
def generate_real_samples (набор данных, n_samples):
# выбираем случайные экземпляры
ix = randint(0, dataset. shape[0], n_samples)
# выберите изображения
X = набор данных[ix]
# генерируем метки классов
y = единицы ((n_samples, 1))
вернуть Х, у
1 2 3 4 5 6 7 8 9 | # выбор реальных образцов def generate_real_samples(dataset, n_samples): # выбор случайных экземпляров ix = randint(0, dataset.shape[0], n_samples) # выбор изображений Xix] # генерировать метки классов y = one((n_samples, 1)) возврат Х, у |
Далее нам нужны входные данные для модели генератора. Это случайные точки из скрытого пространства, в частности случайные величины, распределенные по Гауссу.
Функция generate_latent_points() реализует это, принимая размер скрытого пространства в качестве аргумента и количество требуемых точек и возвращая их в виде пакета входных выборок для модели генератора.
# генерировать точки в скрытом пространстве в качестве входных данных для генератора def generate_latent_points (latent_dim, n_samples): # генерируем точки в скрытом пространстве x_input = randn (latent_dim * n_samples) # преобразовать в пакет входных данных для сети x_input = x_input.reshape (n_samples, скрытый_дим) вернуть x_input
1 2 3 4 5 6 7 | # создать точки в скрытом пространстве в качестве входных данных для генератора def generate_latent_points(latent_dim, n_samples): # создать точки в скрытом пространстве входы для сети x_input = x_input.reshape(n_samples, hidden_dim) возврат x_input |
Далее нам нужно использовать точки в скрытом пространстве в качестве входных данных для генератора, чтобы генерировать новые изображения.
Функция generate_fake_samples() ниже реализует это, принимая модель генератора и размер скрытого пространства в качестве аргументов, затем генерируя точки в скрытом пространстве и используя их в качестве входных данных для модели генератора. Функция возвращает сгенерированные изображения и соответствующую им метку класса для модели дискриминатора, в частности class=0, чтобы указать, что они поддельные или сгенерированные.
# использовать генератор для создания n поддельных примеров с метками классов def generate_fake_samples (генератор, латентный_дим, n_samples): # генерируем точки в скрытом пространстве x_input = generate_latent_points (latent_dim, n_samples) # прогнозировать выходные данные X = генератор.прогноз(x_input) # создаем метки классов у = нули ((n_samples, 1)) возврат Х, у
1 2 3 4 5 6 7 8 9 | # использовать генератор для создания n поддельных примеров с метками классов X = генератор.предсказание(x_input) # создать метки класса y = нули((n_samples, 1)) вернуть X, y |
Нам нужно записать производительность модели. Возможно, самый надежный способ оценить производительность GAN — использовать генератор для создания изображений, а затем просмотреть и субъективно оценить их.
Приведенная ниже функция summ_performance() берет модель генератора в заданный момент во время обучения и использует ее для создания 100 изображений в сетке 10×10, которые затем наносятся на график и сохраняются в файл. В это время модель также сохраняется в файл на случай, если мы захотим использовать ее позже для создания дополнительных изображений.
# сгенерировать образцы и сохранить как график и сохранить модель
defsummary_performance(шаг,g_model,latent_dim,n_samples=100):
# подготовить поддельные примеры
X, _ = generate_fake_samples (g_model, hidden_dim, n_samples)
# шкала от [-1,1] до [0,1]
Х = (Х + 1) / 2,0
# сюжетные изображения
для я в диапазоне (10 * 10):
# определить подсюжет
pyplot.subplot(10, 10, 1 + я)
# отключить ось
pyplot.axis(‘выкл’)
# отображать необработанные пиксельные данные
pyplot. imshow(X[i,:,:, 0], cmap=’gray_r’)
# сохранить график в файл
pyplot.savefig(‘results_baseline/generated_plot_%03d.png’% (шаг+1))
pyplot.close()
# сохранить модель генератора
g_model.save(‘results_baseline/model_%03d.h5’ % (шаг+1))
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 9000. 15 9000 3 9000 2 9000. 15 9000 3 9000 2 9000 3 9000 3 9000 214 9000 3 18 19 | # генерировать образцы и сохранять их как график и сохранять модель defsummary_performance(step,g_model,latent_dim,n_samples=100): # подготовить поддельные примеры X, _ = generate_fake_samples(g_model, hidden_dim, n_samples) # масштабировать от [-1,1] до [0,1] X = (X + 1) / 2. # plot images для i в диапазоне (10 * 10): # определить подзаговор pyplot.subplot(10, 10, 1 + i) # выключить ось pyplot.axis(‘off’) # рисуем необработанные пиксельные данные pyplot.imshow(X[i, :, :, 0], cmap=’gray_r’) # сохраняем график в файл pyplot.savefig(‘results_baseline/generated_plot_%03d.png’ % (step+1)) pyplot.close() # сохранить модель генератора g_model.save(‘results_baseline/model_%03d.h5 ‘ % (шаг+1)) |
В дополнение к качеству изображения рекомендуется отслеживать потери и точность модели с течением времени.
Потери и точность классификации для дискриминатора для реальных и поддельных образцов можно отслеживать для каждого обновления модели, как и потери для генератора для каждого обновления. Затем их можно использовать для создания линейных графиков потерь и точности в конце тренировочного прогона.
Функция plot_history() ниже реализует это и сохраняет результаты в файл.
# создаем линейный график потерь для гана и сохраняем в файл def plot_history (d1_hist, d2_hist, g_hist, a1_hist, a2_hist): # сюжетная потеря pyplot.subplot(2, 1, 1) pyplot.plot(d1_hist, label=’d-real’) pyplot.plot(d2_hist, label=’d-fake’) pyplot.plot (g_hist, метка = ‘ген’) pyplot.легенда() # точность дискриминатора графика pyplot.subplot(2, 1, 2) pyplot.plot(a1_hist, label=’acc-real’) pyplot.plot (a2_hist, метка = ‘acc-fake’) pyplot.легенда() # сохранить график в файл pyplot.savefig(‘results_baseline/plot_line_plot_loss.png’) pyplot.close()
1 2 3 4 5 6 7 8 10 110003 12 13 14 1993 16000313 14 9000.9000 313 14 9000 3 | # создать линейный график потерь для гана и сохранить его в файл0003 pyplot. pyplot.plot(d2_hist, метка=’d-fake’) pyplot.plot(g_hist, метка=’gen’) pyplot. legend() # точность дискриминатора графика pyplot.subplot(2, 1, 2) pyplot.plot(a1_hist, label=’acc-real’) pyplot.plot(a2_hist, label=’acc- fake’) pyplot.legend() # сохранить график в файл pyplot.savefig(‘results_baseline/plot_line_plot_loss.png’) pyplot.close() |
Теперь мы готовы установить модель GAN.
Модель подходит для 10 обучающих эпох, что является произвольным, поскольку модель начинает генерировать правдоподобное число-8 цифр, возможно, после первых нескольких эпох. Используется размер пакета из 128 образцов, и каждая эпоха обучения включает 5851/128 или около 45 пакетов реальных и поддельных образцов и обновлений модели. Таким образом, модель обучается в течение 10 эпох по 45 пакетов или 450 итераций.
Сначала модель дискриминатора обновляется для половины партии реальных образцов, а затем для половины партии поддельных образцов, вместе формируя одну партию обновлений веса. Затем генератор обновляется с помощью составной модели GAN. Важно отметить, что метка класса для фальшивых образцов имеет значение 1 или реальное. Это приводит к обновлению генератора в сторону улучшения генерации реальных образцов в следующей партии.
Приведенная ниже функция train() реализует это, используя определенные модели, набор данных и размер скрытого измерения в качестве аргументов и параметризуя количество эпох и размер пакета с аргументами по умолчанию. Модель генератора сохраняется в конце обучения.
Производительность моделей дискриминатора и генератора сообщается на каждой итерации. Образцы изображений генерируются и сохраняются каждую эпоху, а линейные графики производительности модели создаются и сохраняются в конце прогона.
# обучаем генератор и дискриминатор
def train (g_model, d_model, gan_model, набор данных, hidden_dim, n_epochs = 10, n_batch = 128):
# вычисляем количество батчей за эпоху
bat_per_epo = int(dataset.shape[0]/n_batch)
# рассчитать общее количество итераций на основе партии и эпохи
n_steps = bat_per_epo * n_epochs
# вычислить количество образцов в половине партии
half_batch = int (n_batch / 2)
# готовим списки для хранения статистики каждую итерацию
d1_hist, d2_hist, g_hist, a1_hist, a2_hist = список(), список(), список(), список(), список()
# вручную перечисляем эпохи
для i в диапазоне (n_steps):
# получить случайно выбранные «настоящие» сэмплы
X_real, y_real = generate_real_samples (набор данных, полупакет)
# обновить вес модели дискриминатора
d_loss1, d_acc1 = d_model. train_on_batch(X_real, y_real)
# генерировать «поддельные» примеры
X_fake, y_fake = generate_fake_samples (g_model, hidden_dim, half_batch)
# обновить вес модели дискриминатора
d_loss2, d_acc2 = d_model.train_on_batch(X_fake, y_fake)
# подготовить точки в скрытом пространстве в качестве входных данных для генератора
X_gan = generate_latent_points (latent_dim, n_batch)
# создаем перевернутые метки для поддельных образцов
y_gan = единицы ((n_batch, 1))
# обновить генератор через ошибку дискриминатора
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# суммируем потери в этой партии
print(‘>%d, d1=%.3f, d2=%.3f g=%.3f, a1=%d, a2=%d’ %
(i+1, d_loss1, d_loss2, g_loss, int(100*d_acc1), int(100*d_acc2)))
# запись истории
d1_hist.append(d_loss1)
d2_hist.append(d_loss2)
g_hist.append(g_loss)
a1_hist.append(d_acc1)
a2_hist.append(d_acc2)
# оцениваем производительность модели каждую «эпоху»
если (i+1) % bat_per_epo == 0:
суммарная_производительность (я, g_model, латентный_дим)
plot_history(d1_hist, d2_hist, g_hist, a1_hist, a2_hist)
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 9000 2 14 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 25 26 27 28 29 30 28 29 30 0002 3132 33 34 35 36 37 38 3 3 | # обучаем генератор и дискриминатор def train(g_model, d_model, gan_model, набор данных, скрытое_dim, n_epochs=10, n_batch=128): # вычисляем количество пакетов в эпоху bat_per_epo = int(dataset. # рассчитать общее количество итераций на основе партии и эпохи n_steps = bat_per_epo * n_epochs # вычислить количество выборок в половине пакета half_batch = int(n_batch / 2) # подготовить списки для хранения статистики на каждой итерации = list(), list(), list(), list(), list() # вручную перечислить эпохи для i в диапазоне (n_steps): # получить случайно выбранные «реальные» выборки X_real, y_real = generate_real_samples (набор данных, полупакет) # Обновление веса модели дискриминатора D_LOSS1, D_ACC1 = D_MODEL.TRAIN_ON_BATCH (X_REAL, Y_REAL) # GENERGITE ‘FAKE’ Примеры x_fake, y_fake = Generate_fake_samples (g_model, latent_diM, latent_diM, latent_diM, latent_diM, latent_fake. d_loss2, d_acc2 = d_model.train_on_batch(X_fake, y_fake) # подготовить точки в скрытом пространстве в качестве входных данных для генератора X_gan = generate_latent_points(latent_dim, n_batch) # создать перевернутые метки для поддельных образцов y_gan =ones((n_batch, 1)) #обновить генератор через ошибку дискриминатора этот пакет print(‘>%d, d1=%. (i+1, d_loss1, d_loss2, g_loss, int(100*d_acc1), int(100*d_acc2))) # история записей d1_hist.append(d_loss1) d2_hist.append(d_loss2) g_hist.append(g_loss) a1_hist.append(d_acc1) a2_hist.append(d_acc2) # оценивать производительность модели каждую ‘эпоху’ if (i+1 = 9 % bat_03:epo) суммарная_производительность(i, g_model, латентный_дим) plot_history(d1_hist, d2_hist, g_hist, a1_hist, a2_hist) |
Теперь, когда все функции определены, мы можем создать каталог, в котором будут храниться изображения и модели (в данном случае « results_baseline ’), создайте модели, загрузите набор данных и начните процесс обучения.
# создаем папку для результатов
makedirs(‘results_baseline’, exists_ok=Истина)
# размер скрытого пространства
скрытый_дим = 50
# создаем дискриминатор
дискриминатор = определить_дискриминатор()
# создаем генератор
генератор = определить_генератор (латентный_тусклый)
# создаем ган
gan_model = define_gan (генератор, дискриминатор)
# загрузить данные изображения
набор данных = load_real_samples()
печать (набор данных. форма)
# модель поезда
поезд (генератор, дискриминатор, модель_гана, набор данных, латентный_дим)
1 2 3 4 5 6 7 8 10 110003 12 13 14 9000 15 | # создать папку для результатов makedirs(‘results_baseline’, exists_ok=True) # размер скрытого пространства latent_dim = 50 # создать дискриминатор0003 # создать генератор генератор = определить_генератор(латентный_дим) # создать ган gan_model = определить_ган(генератор, дискриминатор) # загрузить данные изображения ) # модель поезда поезд (генератор, дискриминатор, модель_гана, набор данных, латентный_дим) |
Связывая все это вместе, полный пример приведен ниже.
# пример обучения стабильного гана для генерации рукописной цифры
из ОС импортировать makedirs
из numpy импорта expand_dims
из нулей импорта numpy
из пустых импортных
из numpy. random импортировать randn
из numpy.random импортировать randint
из keras.datasets.mnist импортировать load_data
из keras.optimizers импорт Адама
из keras.models импорт последовательный
из keras.layers импорт плотный
из keras.layers импортировать изменение формы
из keras.layers импортировать Flatten
из keras.layers импортировать Conv2D
из keras.layers импортировать Conv2DTranspose
из keras.layers импортировать LeakyReLU
из keras.initializers импортировать RandomNormal
из matplotlib импортировать pyplot # определить автономную модель дискриминатора
def определить_дискриминатор (in_shape = (28,28,1)):
# инициализация веса
инициализация = случайный нормальный (стандартное отклонение = 0,02)
# определить модель
модель = Последовательный()
# понизить разрешение до 14×14
model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init, input_shape=in_shape))
model.add (LeakyReLU (альфа = 0,2))
# понизить разрешение до 7×7
model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model. add (LeakyReLU (альфа = 0,2))
# классификатор
model.add(Свести())
model.add (плотный (1, активация = ‘сигмоид’))
# скомпилировать модель
opt = Адам (lr = 0,0002, beta_1 = 0,5)
model.compile (потеря = ‘binary_crossentropy’, оптимизатор = опция, метрики = [‘точность’])
модель возврата # определить автономную модель генератора
def определить_генератор (скрытый_дим):
# инициализация веса
инициализация = случайный нормальный (стандартное отклонение = 0,02)
# определить модель
модель = Последовательный()
# основа для изображения 7×7
n_узлов = 128 * 7 * 7
model.add(Dense(n_nodes, kernel_initializer=init, input_dim=latent_dim))
model.add (LeakyReLU (альфа = 0,2))
model.add(Изменить форму((7, 7, 128)))
# повысить разрешение до 14×14
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model.add (LeakyReLU (альфа = 0,2))
# повысить разрешение до 28×28
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model. add (LeakyReLU (альфа = 0,2))
# вывод 28x28x1
model.add (Conv2D (1, (7,7), активация = ‘tanh’, заполнение = ‘то же’, kernel_initializer = init))
модель возврата # определить комбинированную модель генератора и дискриминатора для обновления генератора
def define_gan (генератор, дискриминатор):
# делаем веса в дискриминаторе не обучаемыми
дискриминатор.trainable = Ложь
# соедините их
модель = Последовательный()
# добавляем генератор
model.add(генератор)
# добавляем дискриминатор
model.add(дискриминатор)
# скомпилировать модель
opt = Адам (lr = 0,0002, beta_1 = 0,5)
model.compile (потеря = ‘binary_crossentropy’, оптимизатор = опция)
модель возврата # загрузить изображения mnist
защита load_real_samples():
# загрузить набор данных
(поездX, обучение), (_, _) = load_data()
# расширить до 3D, например. добавить каналы
X = expand_dims (trainX, ось = -1)
# выбрать все примеры для данного класса
selected_ix = обучаемый == 8
Х = Х[выбрано_ix]
# преобразовать из целых чисел в числа с плавающей запятой
X = X. astype(‘float32’)
# шкала от [0,255] до [-1,1]
Х = (Х — 127,5) / 127,5
вернуть Х # выбрать реальные образцы
def generate_real_samples (набор данных, n_samples):
# выбираем случайные экземпляры
ix = randint(0, dataset.shape[0], n_samples)
# выберите изображения
X = набор данных[ix]
# генерируем метки классов
y = единицы ((n_samples, 1))
вернуть х, у # генерировать точки в скрытом пространстве в качестве входных данных для генератора
def generate_latent_points (latent_dim, n_samples):
# генерируем точки в скрытом пространстве
x_input = randn (latent_dim * n_samples)
# преобразовать в пакет входных данных для сети
x_input = x_input.reshape (n_samples, скрытый_дим)
вернуть x_input # использовать генератор для создания n поддельных примеров с метками классов
def generate_fake_samples (генератор, латентный_дим, n_samples):
# генерируем точки в скрытом пространстве
x_input = generate_latent_points (latent_dim, n_samples)
# прогнозировать выходные данные
X = генератор. прогноз(x_input)
# создаем метки классов
у = нули ((n_samples, 1))
вернуть х, у # сгенерировать образцы и сохранить как график и сохранить модель
defsummary_performance(шаг,g_model,latent_dim,n_samples=100):
# подготовить поддельные примеры
X, _ = generate_fake_samples (g_model, hidden_dim, n_samples)
# шкала от [-1,1] до [0,1]
Х = (Х + 1) / 2,0
# сюжетные изображения
для я в диапазоне (10 * 10):
# определить подсюжет
pyplot.subplot(10, 10, 1 + я)
# отключить ось
pyplot.axis(‘выкл’)
# отображать необработанные пиксельные данные
pyplot.imshow(X[i,:,:, 0], cmap=’gray_r’)
# сохранить график в файл
pyplot.savefig(‘results_baseline/generated_plot_%03d.png’% (шаг+1))
pyplot.close()
# сохранить модель генератора
g_model.save(‘results_baseline/model_%03d.h5′ % (шаг+1)) # создаем линейный график потерь для гана и сохраняем в файл
def plot_history (d1_hist, d2_hist, g_hist, a1_hist, a2_hist):
# сюжетная потеря
pyplot.subplot(2, 1, 1)
pyplot.plot(d1_hist, label=’d-real’)
pyplot. plot(d2_hist, label=’d-fake’)
pyplot.plot (g_hist, метка = ‘ген’)
pyplot.легенда()
# точность дискриминатора графика
pyplot.subplot(2, 1, 2)
pyplot.plot(a1_hist, label=’acc-real’)
pyplot.plot (a2_hist, метка = ‘acc-fake’)
pyplot.легенда()
# сохранить график в файл
pyplot.savefig(‘results_baseline/plot_line_plot_loss.png’)
pyplot.close() # обучаем генератор и дискриминатор
def train (g_model, d_model, gan_model, набор данных, hidden_dim, n_epochs = 10, n_batch = 128):
# вычисляем количество батчей за эпоху
bat_per_epo = int(dataset.shape[0]/n_batch)
# рассчитать общее количество итераций на основе партии и эпохи
n_steps = bat_per_epo * n_epochs
# вычислить количество образцов в половине партии
half_batch = int (n_batch / 2)
# готовим списки для хранения статистики каждую итерацию
d1_hist, d2_hist, g_hist, a1_hist, a2_hist = список(), список(), список(), список(), список()
# вручную перечисляем эпохи
для i в диапазоне (n_steps):
# получить случайно выбранные «настоящие» сэмплы
X_real, y_real = generate_real_samples (набор данных, полупакет)
# обновить вес модели дискриминатора
d_loss1, d_acc1 = d_model. train_on_batch(X_real, y_real)
# генерировать «поддельные» примеры
X_fake, y_fake = generate_fake_samples (g_model, hidden_dim, half_batch)
# обновить вес модели дискриминатора
d_loss2, d_acc2 = d_model.train_on_batch(X_fake, y_fake)
# подготовить точки в скрытом пространстве в качестве входных данных для генератора
X_gan = generate_latent_points (latent_dim, n_batch)
# создаем перевернутые метки для поддельных образцов
y_gan = единицы ((n_batch, 1))
# обновить генератор через ошибку дискриминатора
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# суммируем потери в этой партии
print(‘>%d, d1=%.3f, d2=%.3f g=%.3f, a1=%d, a2=%d’ %
(i+1, d_loss1, d_loss2, g_loss, int(100*d_acc1), int(100*d_acc2)))
# запись истории
d1_hist.append(d_loss1)
d2_hist.append(d_loss2)
g_hist.append(g_loss)
a1_hist.append(d_acc1)
a2_hist.append(d_acc2)
# оцениваем производительность модели каждую «эпоху»
если (i+1) % bat_per_epo == 0:
суммарная_производительность (я, g_model, латентный_дим)
plot_history(d1_hist, d2_hist, g_hist, a1_hist, a2_hist) # создаем папку для результатов
makedirs(‘results_baseline’, exists_ok=Истина)
# размер скрытого пространства
скрытый_дим = 50
# создаем дискриминатор
дискриминатор = определить_дискриминатор()
# создаем генератор
генератор = определить_генератор (латентный_тусклый)
# создаем ган
gan_model = define_gan (генератор, дискриминатор)
# загрузить данные изображения
набор данных = load_real_samples()
печать (набор данных. форма)
# модель поезда
поезд (генератор, дискриминатор, модель_гана, набор данных, латентный_дим)
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 9000 2 14 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 25 26 27 28 29 30 28 29 30 0002 3132 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 13121 122 130002 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 151 152 9000 30003 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 7000 183 9000181 1821 183 183 9000 9000 . 0003184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 | # пример обучения стабильного гана для генерации рукописной цифры от OS Import MakedIrs из Numpy Import Expand_dims от Numpy Import Zeros от Numpy Import One от Numpy.random Importnd Randn из Numpy.random Importint из Keras.datasets.m.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manit. из keras.optimizers import Adam из keras.models import Sequential из keras.layers import Dense из keras.layers import Reshape из keras.layers import Flatten from keras. from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU from keras.initializers import RandomNormal from matplotlib import pyplot
# define the standalone discriminator model def Define_Distributor(in_shape=(28,28,1)): # инициализация веса init = RandomNormal(stddev=0.02) # определение модели model = Sequential() # уменьшение разрешения до 14×14 model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init, input_shape=in_shape)) model.add (LeakyReLU(alpha=0.2)) # понижение разрешения до 7×7 model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2)) # классификатор model.add(Flatten()) model.add(Dense(1, активация=’sigmoid’)) # скомпилировать модель opt = Adam(lr=0.0002, beta_1=0. model.compile(loss=’binary_crossentropy’, optimizer=opt, metrics=[‘accuracy’]) return model
# определение автономной Модель генератора DEF DEFINE_GENERATOR (LATENT_DIM): # Инициализация веса init = случайный (stddev = 0,02) # Define Model Модель = 1288 * 10003 # Фонд для 7×7 Изображение n_nodes = 1288 * 7*7 model.add(Dense(n_nodes, kernel_initializer=init, input_dim=latent_dim)) model.add(LeakyReLU(alpha=0.2)) model.add(Reshape((7, 7, 128))) # повысить разрешение до 14×14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2) )) # повысить разрешение до 28×28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2)) # вывод 28x28x1 model.add(Conv2D(1, (7,7), активация=’tanh’, padding=’same’, kernel_initializer=init)) return model
# определить комбинированную модель генератора и дискриминатора для обновления генератора # соедините их model = Sequential() # добавить генератор model. # добавить дискриминатор model.add(дискриминатор) # скомпилировать модель opt = Adam(lr=0.0002, beta 0.5) model.compile(loss=’binary_crossentropy’, optimizer=opt) модель возврата
# загрузить изображения mnist def load_real_samples(): # загрузить набор данных (train ) # загрузить набор данных # загрузить набор данных (_, _) = load_data() # расширить до 3d, например. добавить каналы X = expand_dims(trainX, axis=-1) # выбрать все примеры для данного класса float X = X.astype(‘float32’) # масштаб от [0,255] до [-1,1] X = (X — 127,5) / 127,5 return X # select real образцы def generate_real_samples (набор данных, n_samples): # выбрать случайные экземпляры ix = randint(0, dataset.shape[0], n_samples) # выбрать изображения X = набор данных[ix] # создать метки классов y = one((n_samples) , 1)) return X, y
# генерировать точки в скрытом пространстве в качестве входных данных для генератора скрытый_дим * n_samples) # преобразование в пакет входных данных для сети x_input = x_input. return x_input
# использование генератора для создания n поддельных примеров с метками классов 3 генератор, скрытое_дим, n_samples): # генерировать точки в скрытом пространстве x_input = generate_latent_points(latent_dim, n_samples) # прогнозировать выходные данные X = генератор.предсказать(x_input) # создать метки классов y = zeros((n_samples, 1)) return X, y
# создать образцы и сохранить их как график и сохранить модель , n_samples=100) 1) / 2.0 # изображения графика для i в диапазоне (10 * 10): # определить подзаголовок pyplot.subplot(10, 10, 1 + i) # выключить ось pyplot.axis(‘off’) # построить необработанные пиксельные данные pyXplot.imshow(pyXplot.imshow(pyXplot.imshow) i, :, :, 0], cmap=’gray_r’) # сохранить график в файл pyplot.savefig(‘results_baseline/generated_plot_%03d. pyplot.close( ) # сохранить модель генератора g_model.save(‘results_baseline/model_%03d.h5’ % (шаг+1))
# создать линейный график потерь для гана и сохранить его в файл pyplot.plot(d1_hist, label=’d-real’) pyplot.plot(d2_hist, label=’d-fake’) pyplot.plot(g_hist, label=’gen’) pyplot.legend( ) # точность дискриминатора графика pyplot.subplot(2, 1, 2) pyplot.plot(a1_hist, label=’acc-real’) pyplot.plot(a2_hist, label=’acc-fake’) pyplot.legend() # сохранить график в файл pyplot.savefig(‘results_baseline/plot_line_plot_loss.png’) )
# обучение генератора и дискриминатора def train(g_model, d_model, gan_model, dataset, hidden_dim, n_epochs=10, n_batch=128): # вычисление количества пакетов в эпоху _batch=900 (dataset.shape[0] / n_batch) # вычислить общее количество итераций на основе партии и эпохи n_steps = bat_per_epo * n_epochs # вычислить количество выборок в половине партии d1_hist, d2_hist, g_hist, a1_hist, a2_hist = list(), list(), list(), list(), list() # вручную перечислить эпохи for i in range(n_steps): # получить случайно выбранные «настоящие» образцы x_real, y_real = Generate_Real_Samples (DataSet, Half_batch) # Обновление модели дискриминатора D_LOSS1, D_ACC1 = D_MODEL. # GENERATE ‘FAKE_BATCH (X_REAL, Y_REAL) # GENERATE’ FAKE_BATH. ,latent_dim,half_batch) # обновить веса модели дискриминатора d_loss2, d_acc2 = d_model.train_on_batch(X_fake, y_fake) # подготовить точки в скрытом пространстве в качестве входных данных для генератора X_gan = generate_latent_points(latent_dim, n_batch) # создаем перевернутые метки для поддельных образцов y_gan = one((n_batch, 1)) # обновляем генератор через ошибку дискриминатора g_loss( X_gan, y_gan) # суммировать потери в этой партии print(‘>%d, d1=%.3f, d2=%.3f g=%.3f, a1=%d, a2=%d’ % (i+1, d_loss1, d_loss2, g_loss, int(100*d_acc1), int(100*d_acc2))) # история записи D1_HIST.Append (D_LOSS1) D2_HIST.Append (D_LOSS2) G_HIST.Append (G_LOSS) A1_HIST.APPEND (D_ACC1) A2_HIST.Append (D_ACC2) # ENSEALCHIUTE. ‘ if (i+1) % bat_per_epo == 0: summarize_performance(i, g_model, latent_dim) plot_history(d1_hist, d2_hist, g_hist, a1_hist, a2_hist)
# make folder for results makedirs(‘results_baseline’, exists_ok=True) # Размер скрытого пространства Latent_DIM = 50 # Создать Discinator Discinator = Define_Discriminator () # Создать генератор Генератор = Define_Generator (Latent_DIM) # Create Gan ganer. _GENERATOdataset = load_real_samples() print(dataset.shape) # модель поезда0003 |
Запуск примера выполняется быстро, примерно за 10 минут на современном оборудовании без графического процессора.
Ваши конкретные результаты будут различаться в зависимости от стохастической природы алгоритма обучения. Тем не менее, общая структура тренировок должна быть очень похожей.
Во-первых, потери и точность дискриминатора и потери для модели генератора сообщаются на консоль при каждой итерации обучающего цикла.
Это важно. Стабильная GAN будет иметь потери на дискриминаторе около 0,5, обычно от 0,5 до 0,7 или 0,8. Потери генератора обычно выше и могут колебаться в пределах 1,0, 1,5, 2,0 или даже выше.
Точность дискриминатора как для реальных, так и для сгенерированных (фальшивых) изображений не будет составлять 50 %, но обычно должна колебаться в пределах от 70 % до 80 %.
Как для дискриминатора, так и для генератора поведение, скорее всего, будет вначале неустойчивым и будет меняться много раз, прежде чем модель сойдется к устойчивому равновесию.
>1, d1=0,859, d2=0,664 г=0,872, а1=37, а2=59 >2, d1=0,190, d2=1,429 г=0,555, а1=100, а2=10 >3, d1=0,094, d2=1,467 г=0,597, а1=100, а2=4 >4, d1=0,097, d2=1,315 г=0,686, а1=100, а2=9 >5, d1=0,100, d2=1,241 г=0,714, а1=100, а2=9 … >446, d1=0,593, d2=0,546 г=1,330, а1=76, а2=82 >447, d1=0,551, d2=0,739 г=0,981, а1=82, а2=39 >448, d1=0,628, d2=0,505 г=1,420, а1=79, а2=89 >449, d1=0,641, d2=0,533 г=1,381, а1=60, а2=85 >450, d1=0,550, d2=0,731 g=1,100, a1=76, a2=42
1 2 3 4 5 6 7 8 9 10 11 | >1, d1=0,859, d2=0,664 g=0,872, a1=37, a2=59 >2, d1=0,190, d2=1,429 g=0,555, a1=100, a2=10 >3 , d1=0,094, d2=1,467 g=0,597, a1=100, a2=4 >4, d1=0,097, d2=1,315 g=0,686, a1=100, a2=9 >5, d1=0,100 , d2=1,241 g=0,714, a1=100, a2=9 … >446, d1=0,593, d2=0,546 g=1,330, a1=76, a2=82 >447, d1= 0,551, d2=0,739g=0,981, a1=82, a2=39 >448, d1=0,628, d2=0,505 g=1,420, a1=79, a2=89 >449, d1=0,641, d2=0,533 g=1,381, a1=60, a2=85 >450, d1=0,550, d2=0,731 g=1,100, a1=76, a2=42 |
Линейные графики потерь и точности создаются и сохраняются в конце цикла.
Рисунок содержит два подграфика. На верхнем подграфике показаны линейные графики потерь дискриминатора для реальных изображений (синий), потерь дискриминатора для сгенерированных поддельных изображений (оранжевый) и потерь генератора для сгенерированных поддельных изображений (зеленый).
Мы видим, что все три потери несколько хаотичны в начале прогона, прежде чем стабилизируются между эпохами 100 и 300. После этого потери остаются стабильными, хотя дисперсия увеличивается.
Это пример нормальной или ожидаемой потери во время обучения. А именно, потери дискриминатора для реальных и поддельных образцов примерно одинаковы и составляют около 0,5, а потери для генератора немного выше между 0,5 и 2,0. Если модель генератора способна генерировать правдоподобные изображения, то ожидается, что эти изображения были бы созданы между эпохами 100 и 300, а также, вероятно, между эпохами 300 и 450.
Нижний подграфик показывает линейный график точности дискриминатора на реальных (синих) и поддельных (оранжевых) изображениях во время обучения. Мы видим аналогичную структуру в качестве подграфика потерь, а именно то, что точность начинается совершенно по-разному между двумя типами изображений, затем стабилизируется между эпохами 100 и 300 на уровне от 70% до 80% и остается стабильной после этого, хотя и с повышенной дисперсией.
Масштабы времени (например, количество итераций или периодов обучения) для этих шаблонов и абсолютных значений будут различаться в зависимости от задач и типов моделей GAN, хотя график обеспечивает хорошую основу для того, чего ожидать при обучении стабильной модели GAN.
Линейные графики потерь и точности для стабильной генеративно-состязательной сети
Наконец, мы можем просмотреть образцы сгенерированных изображений. Примечание: мы генерируем изображения, используя обратную карту цветов в градациях серого, что означает, что обычная белая фигура на фоне инвертируется в черную фигуру на белом фоне. Это было сделано для облегчения просмотра сгенерированных цифр.
Как и следовало ожидать, образцы изображений, созданные до эпохи 100, имеют относительно низкое качество.
Образец из 100 сгенерированных изображений рукописного числа 8 в эпоху 45 из стабильной GAN.
Образцы изображений, созданные между эпохами 100 и 300, правдоподобны и, возможно, имеют наилучшее качество.
Образец из 100 сгенерированных изображений рукописного номера 8 в эпоху 180 из стабильной GAN.
И образцы сгенерированных изображений после эпохи 300 остаются правдоподобными, хотя, возможно, имеют больше шума, например. фоновый шум.
Образец из 100 сгенерированных изображений рукописного номера 8 в эпоху 450 из стабильной GAN.
Эти результаты важны, так как они подчеркивают, что генерируемое качество может меняться и действительно меняется в зависимости от пробега, даже после того, как тренировочный процесс становится стабильным.
Большее количество итераций обучения, выходящее за пределы некоторой точки стабильности обучения, может привести к получению изображений более высокого качества, а может и не привести.
Мы можем обобщить эти наблюдения для стабильной тренировки GAN следующим образом:
- Потери дискриминатора на реальных и поддельных изображениях, как ожидается, составят около 0,5. Ожидается, что потери генератора
- на поддельных изображениях будут составлять от 0,5 до 2,0. Ожидается, что точность дискриминатора
- на реальных и поддельных изображениях составит около 80%.
- Ожидается, что разница потерь в генераторе и дискриминаторе останется небольшой.
- Ожидается, что генератор будет производить изображения самого высокого качества в течение периода стабильности.
- Стабильность обучения может ухудшиться в периоды потерь с высокой дисперсией и соответствующих генерируемых изображений более низкого качества.
Теперь, когда у нас есть стабильная модель GAN, мы можем изменить ее, чтобы получить некоторые конкретные случаи сбоев.
При обучении моделей GAN новым проблемам часто встречаются два случая отказа; это коллапс режима и сбой конвергенции.
Как определить сбой режима в генеративно-состязательной сети
Коллапс режима относится к модели генератора, которая способна генерировать только один или небольшое подмножество различных результатов или режимов.
Здесь под режимом понимается выходное распределение, т.е. мультимодальная функция относится к функции с более чем одним пиком или оптимумом. В модели генератора GAN сбой режима означает, что огромное количество точек во входном скрытом пространстве (например, во многих случаях гиперсфера 100 измерений) приводит к одному или небольшому подмножеству сгенерированных изображений.
Сбой режима, также известный как сценарий, — это проблема, возникающая, когда генератор учится сопоставлять несколько различных входных значений z с одной и той же выходной точкой.
— Учебное пособие по NIPS 2016: Генеративно-состязательные сети, 2016.
Коллапс режима можно определить при просмотре большой выборки сгенерированных изображений. Изображения будут иметь низкое разнообразие, при этом одно и то же идентичное изображение или одно и то же небольшое подмножество идентичных изображений будет повторяться много раз.
Коллапс моды также можно определить, просмотрев линейный график потерь модели. На линейном графике будут показаны колебания потерь во времени, особенно в модели генератора, поскольку модель генератора обновляется и переходит от генерации одной моды к другой модели с другими потерями.
Мы можем повредить нашу стабильную сеть GAN, чтобы она страдала от сбоя режима несколькими способами. Возможно, наиболее надежным является прямое ограничение размера скрытого измерения, заставляющее модель генерировать только небольшое подмножество правдоподобных результатов.
В частности, переменная ‘ lant_dim ’ может быть изменена со 100 на 1, и эксперимент будет повторен.
# размер скрытого пространства скрытый_дим = 1
# размер скрытого пространства скрытый_дим = 1 |
Полный список кодов приведен ниже для полноты картины.
# пример обучения нестабильного гана для генерации рукописной цифры
из ОС импортировать makedirs
из numpy импорта expand_dims
из нулей импорта numpy
из пустых импортных
из numpy. random импортировать randn
из numpy.random импортировать randint
из keras.datasets.mnist импортировать load_data
из keras.optimizers импорт Адама
из keras.models импорт последовательный
из keras.layers импорт плотный
из keras.layers импортировать изменение формы
из keras.layers импортировать Flatten
из keras.layers импортировать Conv2D
из keras.layers импортировать Conv2DTranspose
из keras.layers импортировать LeakyReLU
из keras.initializers импортировать RandomNormal
из matplotlib импортировать pyplot # определить автономную модель дискриминатора
def определить_дискриминатор (in_shape = (28,28,1)):
# инициализация веса
инициализация = случайный нормальный (стандартное отклонение = 0,02)
# определить модель
модель = Последовательный()
# понизить разрешение до 14×14
model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init, input_shape=in_shape))
model.add (LeakyReLU (альфа = 0,2))
# понизить разрешение до 7×7
model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model. add (LeakyReLU (альфа = 0,2))
# классификатор
model.add(Свести())
model.add (плотный (1, активация = ‘сигмоид’))
# скомпилировать модель
opt = Адам (lr = 0,0002, beta_1 = 0,5)
model.compile (потеря = ‘binary_crossentropy’, оптимизатор = опция, метрики = [‘точность’])
модель возврата # определить автономную модель генератора
def определить_генератор (скрытый_дим):
# инициализация веса
инициализация = случайный нормальный (стандартное отклонение = 0,02)
# определить модель
модель = Последовательный()
# основа для изображения 7×7
n_узлов = 128 * 7 * 7
model.add(Dense(n_nodes, kernel_initializer=init, input_dim=latent_dim))
model.add (LeakyReLU (альфа = 0,2))
model.add(Изменить форму((7, 7, 128)))
# повысить разрешение до 14×14
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model.add (LeakyReLU (альфа = 0,2))
# повысить разрешение до 28×28
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model. add (LeakyReLU (альфа = 0,2))
# вывод 28x28x1
model.add (Conv2D (1, (7,7), активация = ‘tanh’, заполнение = ‘то же’, kernel_initializer = init))
модель возврата # определить комбинированную модель генератора и дискриминатора для обновления генератора
def define_gan (генератор, дискриминатор):
# делаем веса в дискриминаторе не обучаемыми
дискриминатор.trainable = Ложь
# соедините их
модель = Последовательный()
# добавляем генератор
model.add(генератор)
# добавляем дискриминатор
model.add(дискриминатор)
# скомпилировать модель
opt = Адам (lr = 0,0002, beta_1 = 0,5)
model.compile (потеря = ‘binary_crossentropy’, оптимизатор = опция)
модель возврата # загрузить изображения mnist
защита load_real_samples():
# загрузить набор данных
(поездX, обучение), (_, _) = load_data()
# расширить до 3D, например. добавить каналы
X = expand_dims (trainX, ось = -1)
# выбрать все примеры для данного класса
selected_ix = обучаемый == 8
Х = Х[выбрано_ix]
# преобразовать из целых чисел в числа с плавающей запятой
X = X. astype(‘float32’)
# шкала от [0,255] до [-1,1]
Х = (Х — 127,5) / 127,5
вернуть Х # # выбрать реальные образцы
def generate_real_samples (набор данных, n_samples):
# выбираем случайные экземпляры
ix = randint(0, dataset.shape[0], n_samples)
# выберите изображения
X = набор данных[ix]
# генерируем метки классов
y = единицы ((n_samples, 1))
вернуть х, у # генерировать точки в скрытом пространстве в качестве входных данных для генератора
def generate_latent_points (latent_dim, n_samples):
# генерируем точки в скрытом пространстве
x_input = randn (latent_dim * n_samples)
# преобразовать в пакет входных данных для сети
x_input = x_input.reshape (n_samples, скрытый_дим)
вернуть x_input # использовать генератор для создания n поддельных примеров с метками классов
def generate_fake_samples (генератор, латентный_дим, n_samples):
# генерируем точки в скрытом пространстве
x_input = generate_latent_points (latent_dim, n_samples)
# прогнозировать выходные данные
X = генератор. прогноз(x_input)
# создаем метки классов
у = нули ((n_samples, 1))
вернуть х, у # сгенерировать образцы и сохранить как график и сохранить модель
defsummary_performance(шаг,g_model,latent_dim,n_samples=100):
# подготовить поддельные примеры
X, _ = generate_fake_samples (g_model, hidden_dim, n_samples)
# шкала от [-1,1] до [0,1]
Х = (Х + 1) / 2,0
# сюжетные изображения
для я в диапазоне (10 * 10):
# определить подсюжет
pyplot.subplot(10, 10, 1 + я)
# отключить ось
pyplot.axis(‘выкл’)
# отображать необработанные пиксельные данные
pyplot.imshow(X[i,:,:, 0], cmap=’gray_r’)
# сохранить график в файл
pyplot.savefig(‘results_collapse/generated_plot_%03d.png’% (шаг+1))
pyplot.close()
# сохранить модель генератора
g_model.save(‘results_collapse/model_%03d.h5′ % (шаг+1)) # создаем линейный график потерь для гана и сохраняем в файл
def plot_history (d1_hist, d2_hist, g_hist, a1_hist, a2_hist):
# сюжетная потеря
pyplot.subplot(2, 1, 1)
pyplot.plot(d1_hist, label=’d-real’)
pyplot. plot(d2_hist, label=’d-fake’)
pyplot.plot (g_hist, метка = ‘ген’)
pyplot.легенда()
# точность дискриминатора графика
pyplot.subplot(2, 1, 2)
pyplot.plot(a1_hist, label=’acc-real’)
pyplot.plot (a2_hist, метка = ‘acc-fake’)
pyplot.легенда()
# сохранить график в файл
pyplot.savefig(‘results_collapse/plot_line_plot_loss.png’)
pyplot.close() # обучаем генератор и дискриминатор
def train (g_model, d_model, gan_model, набор данных, hidden_dim, n_epochs = 10, n_batch = 128):
# вычисляем количество батчей за эпоху
bat_per_epo = int(dataset.shape[0]/n_batch)
# рассчитать общее количество итераций на основе партии и эпохи
n_steps = bat_per_epo * n_epochs
# вычислить количество образцов в половине партии
half_batch = int (n_batch / 2)
# готовим списки для хранения статистики каждую итерацию
d1_hist, d2_hist, g_hist, a1_hist, a2_hist = список(), список(), список(), список(), список()
# вручную перечисляем эпохи
для i в диапазоне (n_steps):
# получить случайно выбранные «настоящие» сэмплы
X_real, y_real = generate_real_samples (набор данных, полупакет)
# обновить вес модели дискриминатора
d_loss1, d_acc1 = d_model. train_on_batch(X_real, y_real)
# генерировать «поддельные» примеры
X_fake, y_fake = generate_fake_samples (g_model, hidden_dim, half_batch)
# обновить вес модели дискриминатора
d_loss2, d_acc2 = d_model.train_on_batch(X_fake, y_fake)
# подготовить точки в скрытом пространстве в качестве входных данных для генератора
X_gan = generate_latent_points (latent_dim, n_batch)
# создаем перевернутые метки для поддельных образцов
y_gan = единицы ((n_batch, 1))
# обновить генератор через ошибку дискриминатора
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# суммируем потери в этой партии
print(‘>%d, d1=%.3f, d2=%.3f g=%.3f, a1=%d, a2=%d’ %
(i+1, d_loss1, d_loss2, g_loss, int(100*d_acc1), int(100*d_acc2)))
# запись истории
d1_hist.append(d_loss1)
d2_hist.append(d_loss2)
g_hist.append(g_loss)
a1_hist.append(d_acc1)
a2_hist.append(d_acc2)
# оцениваем производительность модели каждую «эпоху»
если (i+1) % bat_per_epo == 0:
суммарная_производительность (я, g_model, латентный_дим)
plot_history(d1_hist, d2_hist, g_hist, a1_hist, a2_hist) # создаем папку для результатов
makedirs(‘results_collapse’, exists_ok=True)
# размер скрытого пространства
скрытый_дим = 1
# создаем дискриминатор
дискриминатор = определить_дискриминатор()
# создаем генератор
генератор = определить_генератор (латентный_тусклый)
# создаем ган
gan_model = define_gan (генератор, дискриминатор)
# загрузить данные изображения
набор данных = load_real_samples()
печать (набор данных. форма)
# модель поезда
поезд (генератор, дискриминатор, модель_гана, набор данных, латентный_дим)
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 9000 2 14 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 25 26 27 28 29 30 28 29 30 0002 3132 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 13121 122 130002 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 151 152 9000 30003 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 7000 183 9000181 1821 183 183 9000 9000 . 0003184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 | # пример обучения нестабильного гана для генерации рукописной цифры от OS Import MakedIrs из Numpy Import Expand_dims от Numpy Import Zeros от Numpy Import One от Numpy.random Importnd Randn из Numpy.random Importint из Keras.datasets.m.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manit. из keras.optimizers import Adam из keras.models import Sequential из keras.layers import Dense из keras.layers import Reshape из keras.layers import Flatten from keras. from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU from keras.initializers import RandomNormal from matplotlib import pyplot
# define the standalone discriminator model def Define_Distributor(in_shape=(28,28,1)): # инициализация веса init = RandomNormal(stddev=0.02) # определение модели model = Sequential() # уменьшение разрешения до 14×14 model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init, input_shape=in_shape)) model.add (LeakyReLU(alpha=0.2)) # понижение разрешения до 7×7 model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2)) # классификатор model.add(Flatten()) model.add(Dense(1, активация=’sigmoid’)) # скомпилировать модель opt = Adam(lr=0.0002, beta_1=0. model.compile(loss=’binary_crossentropy’, optimizer=opt, metrics=[‘accuracy’]) return model
# определение автономной Модель генератора DEF DEFINE_GENERATOR (LATENT_DIM): # Инициализация веса init = случайный (stddev = 0,02) # Define Model Модель = 1288 * 10003 # Фонд для 7×7 Изображение n_nodes = 1288 * 7*7 model.add(Dense(n_nodes, kernel_initializer=init, input_dim=latent_dim)) model.add(LeakyReLU(alpha=0.2)) model.add(Reshape((7, 7, 128))) # повысить разрешение до 14×14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2) )) # повысить разрешение до 28×28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2)) # вывод 28x28x1 model.add(Conv2D(1, (7,7), активация=’tanh’, padding=’same’, kernel_initializer=init)) return model
# определить комбинированную модель генератора и дискриминатора для обновления генератора # соедините их model = Sequential() # добавить генератор model. # добавить дискриминатор model.add(дискриминатор) # скомпилировать модель opt = Adam(lr=0.0002, beta 0.5) model.compile(loss=’binary_crossentropy’, optimizer=opt) модель возврата
# загрузить изображения mnist def load_real_samples(): # загрузить набор данных (train ) # загрузить набор данных # загрузить набор данных (_, _) = load_data() # расширить до 3d, например. добавить каналы X = expand_dims(trainX, axis=-1) # выбрать все примеры для данного класса float X = X.astype(‘float32’) # масштаб от [0,255] до [-1,1] X = (X — 127,5) / 127,5 return X
# select реальные образцы def generate_real_samples (набор данных, n_samples): # выбрать случайные экземпляры ix = randint(0, dataset.shape[0], n_samples) # выбрать изображения X = набор данных[ix] # создать метки классов y = one((n_samples) , 1)) return X, y
# генерировать точки в скрытом пространстве в качестве входных данных для генератора скрытый_дим * n_samples) # преобразование в пакет входных данных для сети x_input = x_input. return x_input
# использование генератора для создания n поддельных примеров с метками классов 3 генератор, скрытое_дим, n_samples): # генерировать точки в скрытом пространстве x_input = generate_latent_points(latent_dim, n_samples) # прогнозировать выходные данные X = генератор.предсказать(x_input) # создать метки классов y = zeros((n_samples, 1)) return X, y
# создать образцы и сохранить их как график и сохранить модель , n_samples=100) 1) / 2.0 # изображения графика для i в диапазоне (10 * 10): # определить подзаголовок pyplot.subplot(10, 10, 1 + i) # выключить ось pyplot.axis(‘off’) # построить необработанные пиксельные данные pyXplot.imshow(pyXplot.imshow(pyXplot.imshow) i, :, :, 0], cmap=’gray_r’) # сохранить график в файл pyplot.savefig(‘results_collapse/generated_plot_%03d. pyplot.close( ) # сохранить модель генератора g_model.save(‘results_collapse/model_%03d.h5’ % (шаг+1))
# создать линейный график потерь для гана и сохранить его в файл pyplot.plot(d1_hist, label=’d-real’) pyplot.plot(d2_hist, label=’d-fake’) pyplot.plot(g_hist, label=’gen’) pyplot.legend( ) # точность дискриминатора графика pyplot.subplot(2, 1, 2) pyplot.plot(a1_hist, label=’acc-real’) pyplot.plot(a2_hist, label=’acc-fake’) pyplot.legend() # сохранить график в файл pyplot.savefig(‘results_collapse/plot_line_plot_loss.png’) )
# обучение генератора и дискриминатора def train(g_model, d_model, gan_model, dataset, hidden_dim, n_epochs=10, n_batch=128): # вычисление количества пакетов в эпоху _batch=900 (dataset.shape[0] / n_batch) # вычислить общее количество итераций на основе партии и эпохи n_steps = bat_per_epo * n_epochs # вычислить количество выборок в половине партии d1_hist, d2_hist, g_hist, a1_hist, a2_hist = list(), list(), list(), list(), list() # вручную перечислить эпохи for i in range(n_steps): # получить случайно выбранные «настоящие» образцы x_real, y_real = Generate_Real_Samples (DataSet, Half_batch) # Обновление модели дискриминатора D_LOSS1, D_ACC1 = D_MODEL. # GENERATE ‘FAKE_BATCH (X_REAL, Y_REAL) # GENERATE’ FAKE_BATH. ,latent_dim,half_batch) # обновить веса модели дискриминатора d_loss2, d_acc2 = d_model.train_on_batch(X_fake, y_fake) # подготовить точки в скрытом пространстве в качестве входных данных для генератора X_gan = generate_latent_points(latent_dim, n_batch) # создаем перевернутые метки для поддельных образцов y_gan = one((n_batch, 1)) # обновляем генератор через ошибку дискриминатора g_loss( X_gan, y_gan) # суммировать потери в этой партии print(‘>%d, d1=%.3f, d2=%.3f g=%.3f, a1=%d, a2=%d’ % (i+1, d_loss1, d_loss2, g_loss, int(100*d_acc1), int(100*d_acc2))) # история записи D1_HIST.Append (D_LOSS1) D2_HIST.Append (D_LOSS2) G_HIST.Append (G_LOSS) A1_HIST.APPEND (D_ACC1) A2_HIST.Append (D_ACC2) # ENSEALCHIUTE. ‘ if (i+1) % bat_per_epo == 0: summarize_performance(i, g_model, latent_dim) plot_history(d1_hist, d2_hist, g_hist, a1_hist, a2_hist)
# make folder for results makedirs(‘results_collapse’, exists_ok=True) # Размер скрытого пространства latent_dim = 1 # Создать дискриминатор Discinator = define_discriminator () # создать генератор Генератор = Define_generator (Latent_DIM) # CREATE GAN generarator.dataset = load_real_samples() print(dataset.shape) # модель поезда0003 |
Запуск примера будет сообщать о потерях и точности на каждом этапе обучения, как и раньше.
В этом случае потери для дискриминатора находятся в разумном диапазоне, хотя потери для генератора прыгают вверх и вниз. Точность дискриминатора также показывает более высокие значения, многие из которых составляют около 100%, а это означает, что для многих партий он отлично справляется с идентификацией реальных или поддельных примеров, что является плохим признаком качества или разнообразия изображений.
>1, d1=0,963, d2=0,699 г=0,614, а1=28, а2=54 >2, d1=0,185, d2=5,084 g=0,097, а1=96, а2=0 >3, d1=0,088, d2=4,861 г=0,065, а1=100, а2=0 >4, d1=0,077, d2=4,202 г=0,090, а1=100, а2=0 >5, d1=0,062, d2=3,533 g=0,128, а1=100, а2=0 … >446, d1=0,277, d2=0,261 г=0,684, а1=95, а2=100 >447, d1=0,201, d2=0,247 г=0,713, а1=96, а2=100 >448, d1=0,285, d2=0,285 г=0,728, а1=89, а2=100 >449, d1=0,351, d2=0,467 г=1,184, а1=92, а2=81 >450, d1=0,492, d2=0,388 g=1,351, a1=76, a2=100
1 2 3 4 5 6 7 8 10 11 | >1, d1=0,963, d2=0,699 g=0,614, a1=28, a2=54 >2, d1=0,185, d2=5,084 g=0,097, a1=96, a2=0 >3 , d1=0,088, d2=4,861 g=0,065, a1=100, a2=0 >4, d1=0,077, d2=4,202 g=0,090, a1=100, a2=0 >5, d1=0,062 , d2=3,533 г=0,128, а1=100, а2=0, . >446, d1=0,277, d2=0,261 g=0,684, a1=95, a2=100 >447, d1=0,201, d2=0,247 g=0,713, a1=96, a2= 100 >448, d1=0,285, d2=0,285 g=0,728, a1=89, a2=100 >449, d1=0,351, d2=0,467 g=1,184, a1=92, a2=81 > 450, d1=0,492, d2=0,388 г=1,351, а1=76, а2=100 |
Создается и сохраняется рисунок с кривой обучения и графиками линий точности.
На верхнем подграфике мы видим, что потери для генератора (зеленые) колеблются от разумных до высоких значений с течением времени с периодом около 25 обновлений модели (пакетов). Мы также можем видеть небольшие колебания в потерях для дискриминатора на реальных и поддельных образцах (оранжевый и синий).
На нижнем графике видно, что точность классификации дискриминатора для идентификации поддельных изображений остается высокой на протяжении всего цикла. Это говорит о том, что генератор не умеет генерировать примеры последовательным образом, что облегчает дискриминатору идентификацию поддельных изображений.
Линейные графики потерь и точности для генеративно-состязательной сети с коллапсом режима
Просмотр сгенерированных изображений показывает ожидаемую особенность коллапса режима, а именно множество идентичных сгенерированных примеров, независимо от точки ввода в скрытом пространстве. Так уж получилось, что мы изменили размерность скрытого пространства, сделав ее очень малой, чтобы усилить этот эффект.
Я выбрал пример сгенерированных изображений, чтобы было понятно. Кажется, что на изображении всего несколько типов восьмерок: одна наклонена влево, одна наклонена вправо и одна сидит с размытием.
Я обвел прямоугольниками некоторые из подобных примеров на изображении ниже, чтобы было понятнее.
Образец из 100 сгенерированных изображений рукописного числа 8 в эпоху 315 из GAN, в которой произошел сбой режима.
Сбой режима менее распространен во время обучения, учитывая результаты архитектуры модели DCGAN и конфигурации обучения.
Таким образом, вы можете определить сбой режима следующим образом:
- Ожидается, что потери генератора и, возможно, дискриминатора будут колебаться со временем.
- Ожидается, что модель генератора будет генерировать идентичные выходные изображения из разных точек скрытого пространства.
Как определить сбой конвергенции в генеративно-состязательной сети
Пожалуй, наиболее распространенный сбой при обучении GAN — это сбой сходимости.
Как правило, нейронная сеть не может сходиться, если потери модели не стабилизируются в процессе обучения. В случае GAN сбой при сходимости означает невозможность найти равновесие между дискриминатором и генератором.
Скорее всего, вы обнаружите этот тип сбоя, если потеря для дискриминатора стала нулевой или близкой к нулю. В некоторых случаях потери генератора также могут увеличиваться и продолжать расти в течение того же периода.
Этот тип потери чаще всего вызван тем, что генератор выводит изображения мусора, которые дискриминатор может легко идентифицировать.
Этот тип сбоя может произойти в начале прогона и продолжаться на протяжении всей тренировки, после чего вы должны остановить процесс тренировки. Для некоторых нестабильных GAN GAN может попасть в этот режим сбоя в течение ряда пакетных обновлений или даже нескольких эпох, а затем восстановиться.
Существует много способов повредить нашу стабильную GAN для достижения сбоя сходимости, например, изменить одну или обе модели, чтобы они имели недостаточную емкость, изменить алгоритм оптимизации Адама, чтобы он был слишком агрессивным, и использовать очень большие или очень маленькие размеры ядра в моделях. .
В этом случае мы обновим пример, чтобы объединить настоящие и поддельные образцы при обновлении дискриминатора. Это простое изменение приведет к тому, что модель не сойдется.
Это изменение так же просто, как использование функции vstack() NumPy для объединения реальных и поддельных образцов, а затем вызов функции train_on_batch() для обновления модели дискриминатора. Результатом также являются единые оценки потерь и точности, а это означает, что отчеты о производительности модели также должны быть обновлены.
Полный список кодов с этими изменениями приведен ниже для полноты картины.
# пример обучения нестабильного гана для генерации рукописной цифры
из ОС импортировать makedirs
из numpy импорта expand_dims
из нулей импорта numpy
из пустых импортных
импорт из numpy vstack
из numpy.random импортировать randn
из numpy.random импортировать randint
из keras.datasets.mnist импортировать load_data
из keras.optimizers импорт Адама
из keras.models импорт последовательный
из keras.layers импорт плотный
из keras.layers импортировать изменение формы
из keras.layers импортировать Flatten
из keras.layers импортировать Conv2D
из keras.layers импортировать Conv2DTranspose
из keras.layers импортировать LeakyReLU
из keras.initializers импортировать RandomNormal
из matplotlib импортировать pyplot # определить автономную модель дискриминатора
def определить_дискриминатор (in_shape = (28,28,1)):
# инициализация веса
инициализация = случайный нормальный (стандартное отклонение = 0,02)
# определить модель
модель = Последовательный()
# понизить разрешение до 14×14
model. add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init, input_shape=in_shape))
model.add (LeakyReLU (альфа = 0,2))
# понизить разрешение до 7×7
model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model.add (LeakyReLU (альфа = 0,2))
# классификатор
model.add(Свести())
model.add (плотный (1, активация = ‘сигмоид’))
# скомпилировать модель
opt = Адам (lr = 0,0002, beta_1 = 0,5)
model.compile (потеря = ‘binary_crossentropy’, оптимизатор = опция, метрики = [‘точность’])
модель возврата # определить автономную модель генератора
def определить_генератор (скрытый_дим):
# инициализация веса
инициализация = случайный нормальный (стандартное отклонение = 0,02)
# определить модель
модель = Последовательный()
# основа для изображения 7×7
n_узлов = 128 * 7 * 7
model.add(Dense(n_nodes, kernel_initializer=init, input_dim=latent_dim))
model.add (LeakyReLU (альфа = 0,2))
model.add(Изменить форму((7, 7, 128)))
# повысить разрешение до 14×14
model. add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model.add (LeakyReLU (альфа = 0,2))
# повысить разрешение до 28×28
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model.add (LeakyReLU (альфа = 0,2))
# вывод 28x28x1
model.add (Conv2D (1, (7,7), активация = ‘tanh’, заполнение = ‘то же’, kernel_initializer = init))
модель возврата # определить комбинированную модель генератора и дискриминатора для обновления генератора
def define_gan (генератор, дискриминатор):
# делаем веса в дискриминаторе не обучаемыми
дискриминатор.trainable = Ложь
# соедините их
модель = Последовательный()
# добавляем генератор
model.add(генератор)
# добавляем дискриминатор
model.add(дискриминатор)
# скомпилировать модель
opt = Адам (lr = 0,0002, beta_1 = 0,5)
model.compile (потеря = ‘binary_crossentropy’, оптимизатор = опция)
модель возврата # загрузить изображения mnist
защита load_real_samples():
# загрузить набор данных
(поездX, обучение), (_, _) = load_data()
# расширить до 3D, например. добавить каналы
X = expand_dims (trainX, ось = -1)
# выбрать все примеры для данного класса
selected_ix = обучаемый == 8
Х = Х[выбрано_ix]
# преобразовать из целых чисел в числа с плавающей запятой
X = X.astype(‘float32’)
# шкала от [0,255] до [-1,1]
Х = (Х — 127,5) / 127,5
вернуть Х # # выбрать реальные образцы
def generate_real_samples (набор данных, n_samples):
# выбираем случайные экземпляры
ix = randint(0, dataset.shape[0], n_samples)
# выберите изображения
X = набор данных[ix]
# генерируем метки классов
y = единицы ((n_samples, 1))
вернуть х, у # генерировать точки в скрытом пространстве в качестве входных данных для генератора
def generate_latent_points (latent_dim, n_samples):
# генерируем точки в скрытом пространстве
x_input = randn (latent_dim * n_samples)
# преобразовать в пакет входных данных для сети
x_input = x_input.reshape (n_samples, скрытый_дим)
вернуть x_input # использовать генератор для создания n поддельных примеров с метками классов
def generate_fake_samples (генератор, латентный_дим, n_samples):
# генерируем точки в скрытом пространстве
x_input = generate_latent_points (latent_dim, n_samples)
# прогнозировать выходные данные
X = генератор. прогноз(x_input)
# создаем метки классов
у = нули ((n_samples, 1))
вернуть х, у # сгенерировать образцы и сохранить как график и сохранить модель
defsummary_performance(шаг,g_model,latent_dim,n_samples=100):
# подготовить поддельные примеры
X, _ = generate_fake_samples (g_model, hidden_dim, n_samples)
# шкала от [-1,1] до [0,1]
Х = (Х + 1) / 2,0
# сюжетные изображения
для я в диапазоне (10 * 10):
# определить подсюжет
pyplot.subplot(10, 10, 1 + я)
# отключить ось
pyplot.axis(‘выкл’)
# отображать необработанные пиксельные данные
pyplot.imshow(X[i,:,:, 0], cmap=’gray_r’)
# сохранить график в файл
pyplot.savefig(‘results_convergence/generated_plot_%03d.png’% (шаг+1))
pyplot.close()
# сохранить модель генератора
g_model.save(‘results_convergence/model_%03d.h5’ % (шаг+1)) # создаем линейный график потерь для гана и сохраняем в файл
def plot_history (d_hist, g_hist, a_hist):
# сюжетная потеря
pyplot.subplot(2, 1, 1)
pyplot.plot (d_hist, метка = ‘дис’)
pyplot.plot (g_hist, метка = ‘ген’)
pyplot. легенда()
# точность дискриминатора графика
pyplot.subplot(2, 1, 2)
pyplot.plot (a_hist, метка = ‘акк’)
pyplot.легенда()
# сохранить график в файл
pyplot.savefig(‘results_convergence/plot_line_plot_loss.png’)
pyplot.close() # обучаем генератор и дискриминатор
def train (g_model, d_model, gan_model, набор данных, hidden_dim, n_epochs = 10, n_batch = 128):
# вычисляем количество батчей за эпоху
bat_per_epo = int(dataset.shape[0]/n_batch)
# рассчитать общее количество итераций на основе партии и эпохи
n_steps = bat_per_epo * n_epochs
# вычислить количество образцов в половине партии
half_batch = int (n_batch / 2)
# готовим списки для хранения статистики каждую итерацию
d_hist, g_hist, a_hist = список(), список(), список()
# вручную перечисляем эпохи
для i в диапазоне (n_steps):
# получить случайно выбранные «настоящие» сэмплы
X_real, y_real = generate_real_samples (набор данных, полупакет)
# генерировать «поддельные» примеры
X_fake, y_fake = generate_fake_samples (g_model, hidden_dim, half_batch)
# объединить в одну партию
X, y = vstack((X_real, X_fake)), vstack((y_real, y_fake))
# обновить вес модели дискриминатора
d_loss, d_acc = d_model. train_on_batch(X, y)
# подготовить точки в скрытом пространстве в качестве входных данных для генератора
X_gan = generate_latent_points (latent_dim, n_batch)
# создаем перевернутые метки для поддельных образцов
y_gan = единицы ((n_batch, 1))
# обновить генератор через ошибку дискриминатора
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# суммируем потери в этой партии
print(‘>%d, d=%.3f, g=%.3f, a=%d’ % (i+1, d_loss, g_loss, int(100*d_acc)))
# запись истории
d_hist.append(d_loss)
g_hist.append(g_loss)
a_hist.append(d_acc)
# оцениваем производительность модели каждую «эпоху»
если (i+1) % bat_per_epo == 0:
суммарная_производительность (я, g_model, латентный_дим)
plot_history(d_hist, g_hist, a_hist) # создаем папку для результатов
makedirs(‘results_convergence’, exists_ok=True)
# размер скрытого пространства
скрытый_дим = 50
# создаем дискриминатор
дискриминатор = определить_дискриминатор()
# создаем генератор
генератор = определить_генератор (латентный_тусклый)
# создаем ган
gan_model = define_gan (генератор, дискриминатор)
# загрузить данные изображения
набор данных = load_real_samples()
печать (набор данных. форма)
# модель поезда
поезд (генератор, дискриминатор, модель_гана, набор данных, латентный_дим)
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 9000 2 14 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 25 26 27 28 29 30 28 29 30 0002 3132 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 13121 122 130002 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 151 152 9000 30003 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 7000 183 9000181 1821 183 183 9000 9000 . 0003184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 | # пример обучения нестабильного гана для генерации рукописной цифры от OS Import MakedIrs из Numpy Import Expand_dims от Numpy Import Zeros от Numpy Import Ones от Numpy Import VSTACK от Numpy.Random Importn от Nump. .datasets.mnist import load_data из keras.optimizers import Adam из keras.models import Sequential из keras.layers import Dense из keras.layers import Reshape from keras.layers import Flatten from keras.layers import Conv2D from keras.layers import Conv2DTranspose from keras.layers import LeakyReLU from keras. from matplotlib import pyplot
# определить автономную модель дискриминатора def define_distributor(in_shape=(28,28,1)): # инициализация веса init = RandomNormal(stddev=0.02) # определение модели model = Sequential() # понижение разрешения до 14×14 model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer= init, input_shape=in_shape)) model.add(LeakyReLU(alpha=0.2)) # понижение разрешения до 7×7 model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2)) # классификатор model.add(Flatten()) model.add(Dense(1,activation=’sigmoid’)) # скомпилировать модель opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss=’binary_crossentropy’, optimizer=opt , metrics=[‘accuracy’]) модель возврата
# определение модели автономного генератора def define_generator(latent_dim): # инициализация веса модель модель = последовательная() # основа для изображения 7×7 n_nodes = 128 * 7 * 7 model. model.add(LeakyReLU(alpha=0.2)) 3 model.add(Reshape((7, 7, 128)))# повысить разрешение до 14×14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’ , kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2)) # повысить разрешение до 28×28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding) =’такое же’, kernel_initializer=init)) model.add(LeakyReLU(alpha=0.2)) # вывод 28x28x1 model.add(Conv2D(1, (7,7), активация=’tanh’, padding=’same’, kernel_initializer=init) ) return model
# определение комбинированной модели генератора и дискриминатора для обновления генератора # соедините их model = Sequential() # добавить генератор model.add(generator) # добавить дискриминатор model.add(дискриминатор) # скомпилировать модель opt = Adam(10_0,0. model.compile(loss=’binary_crossentropy’, optimizer=opt) return model
# загрузить изображения mnist def load_real_samples(): # train # загрузить набор данных 900X , (_, _) = load_data() # расширить до 3d, например. добавить каналы X = expand_dims(trainX, axis=-1) # выбрать все примеры для данного класса float X = X.astype(‘float32’) # масштаб от [0,255] до [-1,1] X = (X — 127,5) / 127,5 return X
# select реальные образцы def generate_real_samples (набор данных, n_samples): # выбрать случайные экземпляры ix = randint(0, dataset.shape[0], n_samples) # выбрать изображения X = набор данных[ix] # создать метки классов y = one((n_samples) , 1)) return X, y
# генерировать точки в скрытом пространстве в качестве входных данных для генератора скрытый_дим * n_samples) # преобразование в пакет входных данных для сети x_input = x_input. return x_input
# использование генератора для создания n поддельных примеров с метками классов 3 генератор, скрытое_дим, n_samples): # генерировать точки в скрытом пространстве x_input = generate_latent_points(latent_dim, n_samples) # прогнозировать выходные данные X = генератор.предсказать(x_input) # создать метки классов y = zeros((n_samples, 1)) return X, y
# создать образцы и сохранить их как график и сохранить модель , n_samples=100) 1) / 2.0 # изображения графика для i в диапазоне (10 * 10): # определить подзаголовок pyplot.subplot(10, 10, 1 + i) # выключить ось pyplot.axis(‘off’) # построить необработанные пиксельные данные pyXplot.imshow(pyXplot.imshow(pyXplot.imshow) i, :, :, 0], cmap=’gray_r’) # сохранить график в файл pyplot.savefig(‘results_convergence/generated_plot_%03d. pyplot.close( ) # сохранить модель генератора g_model.save(‘results_convergence/model_%03d.h5’ % (шаг+1))
# создать линейный график потерь для гана и сохранить в файл (d_hist, label=’dis’) pyplot.plot(g_hist, label=’gen’) pyplot.legend() # Точность дискриминатора графика pyplot.subplot(2, 1, 2) pyplot.plot(a_hist, label=’acc’) pyplot.legend() # сохранить график в файл pyplot.savefig(‘results_convergence/plot_line_plot_loss.png’) pyplot.close()
# обучение генератора и дискриминатора =128)0002 # вычислить количество выборок в половине партии half_batch = int(n_batch / 2) # подготовить списки для хранения статистики на каждой итерации d_hist, g_hist, a_hist = list(), list(), list() # вручную перечислить эпохи для i в диапазоне (n_steps): # получить случайным образом выбранные «настоящие» выборки y_fake = generate_fake_samples(g_model, hidden_dim, half_batch) # объединить в один пакет X, y = vstack((X_real, X_fake)), vstack((y_real, y_fake)) # обновить веса модели дискриминатора d_loss, d_acc = d_model. # подготовить точки в скрытом пространстве в качестве входных данных для генератора генератор через ошибку дискриминатора g_loss = gan_model.train_on_batch(X_gan, y_gan) # суммировать потери в этой партии print(‘>%d, d=%.3f, g=%.3f, a=%d’ % (i+ 1, d_loss, g_loss, int(100*d_acc))) # история записи d_hist.append(d_loss) g_hist.append(g_loss) a_hist.append(d_acc) # оценка производительности модели каждую «эпоху» if (i+1) % bat_per_epo == 0: summary_performance(i,g_model,latent_dim) plot_history(d_hist,g_hist,a_hist) # Сделать папку для результатов MakedIrs (‘Result_convergence’, ESIGE_OK = TRUE) # Размер латентного пространства Latent_DIM = 50 # Create the Discinator Discinator = DEFINT_DISCRIMINATO создать генератор генератор = определить_генератор(латентный_дим) # создать ган ган_модель = определить_ган(генератор, дискриминатор) # загрузить данные изображения набор данных = load_real_samples() print(dataset. # модель поезда train(генератор, дискриминатор, gan_model, набор данных, латентный_дим) |
Выполнение примера сообщает о потерях и точности для каждого обновления модели.
Явным признаком этого типа отказа является быстрое падение потерь дискриминатора до нуля, где они остаются.
Вот что мы видим в данном случае.
>1, д=0,514, г=0,969, а=80 >2, д=0,475, г=0,395, а=74 >3, д=0,452, г=0,223, а=69>4, д=0,302, г=0,220, а=85 >5, д=0,177, г=0,195, а=100 >6, д=0,122, г=0,200, а=100 >7, д=0,088, г=0,179, а=100 >8, д=0,075, г=0,159, а=100 >9, д=0,071, г=0,167, а=100 >10, д=0,102, г=0,127, а=100 … >446, д=0,000, г=0,001, а=100 >447, д=0,000, г=0,001, а=100 >448, д=0,000, г=0,001, а=100 >449, д=0,000, г=0,001, а=100 >450, d=0,000, g=0,001, а=100
1 2 3 4 5 6 7 8 10 11 12 13 14 16 | >1, d=0,514, g=0,969, a=80 >2, d=0,475, g=0,395, a=74 >3, d=0,452, g=0,223, a=69 >4, d=0,302, g=0,220, a=85 >5, d=0,177, g=0,195, a=100 >6, d=0,122, g=0,200, a=100 >7, d=0,088, g=0,179, a=100 >8, d=0,075, g=0,159, a=100 >9, d=0,071, g=0,167, a=100 >10, d=0,102, g=0,127, a=100 . >446, d=0,000, g=0,001, a=100 >447, d=0,000, g=0,001, a= 100 >448, d=0,000, g=0,001, a=100 >449, d=0,000, g=0,001, a=100 >450, d=0,000, g=0,001, a=100 |
Созданы линейные графики кривых обучения и точности классификации.
Верхний подграфик показывает потери для дискриминатора (синий) и генератора (оранжевый) и четко показывает падение обоих значений до нуля в течение первых 20–30 итераций, где они остаются до конца цикла.
Нижний подграфик показывает, что точность классификации дискриминатора составляет 100 % за тот же период, что означает, что модель идеально подходит для идентификации реальных и поддельных изображений. Ожидается, что в поддельных изображениях есть что-то, что делает их очень легкими для распознавания.
Линейные графики потерь и точности для генеративно-состязательной сети с ошибкой сходимости
Наконец, просмотр образцов сгенерированных изображений проясняет, почему дискриминатор так успешен.
Образцы изображений, созданных в каждую эпоху, очень низкого качества, демонстрируя статические помехи, возможно, со слабой восьмеркой на заднем плане.
Образец из 100 сгенерированных изображений рукописного числа 8 в эпоху 450 из GAN, в которой произошел сбой конвергенции, посредством комбинированных обновлений дискриминатора.
Полезно увидеть еще один пример этого типа сбоя.
В этом случае конфигурация алгоритма оптимизации Адама может быть изменена для использования значений по умолчанию, что, в свою очередь, делает обновления моделей агрессивными и приводит к тому, что процесс обучения не может найти точку равновесия между обучением двух моделей.
Например, дискриминатор можно составить так:
… # скомпилировать модель model.compile(потеря=’binary_crossentropy’, оптимизатор=’адам’, метрики=[‘точность’])
… # скомпилировать модель model.compile(loss=’binary_crossentropy’, Optimizer=’adam’, metrics=[‘accuracy’]) |
А составную модель GAN можно составить следующим образом:
. ..
# скомпилировать модель
model.compile(потеря=’binary_crossentropy’, оптимизатор=’адам’)
… # скомпилировать модель model.compile(потеря=’binary_crossentropy’, оптимизатор=’адам’) |
Полный список кодов приведен ниже для полноты картины.
# пример обучения нестабильного гана для генерации рукописной цифры
из ОС импортировать makedirs
из numpy импорта expand_dims
из нулей импорта numpy
из пустых импортных
из numpy.random импортировать randn
из numpy.random импортировать randint
из keras.datasets.mnist импортировать load_data
из keras.models импорт последовательный
из keras.layers импорт плотный
из keras.layers импортировать изменение формы
из keras.layers импортировать Flatten
из keras.layers импортировать Conv2D
из keras.layers импортировать Conv2DTranspose
из keras.layers импортировать LeakyReLU
из keras.initializers импортировать RandomNormal
из matplotlib импортировать pyplot # определить автономную модель дискриминатора
def определить_дискриминатор (in_shape = (28,28,1)):
# инициализация веса
инициализация = случайный нормальный (стандартное отклонение = 0,02)
# определить модель
модель = Последовательный()
# понизить разрешение до 14×14
model. add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init, input_shape=in_shape))
model.add (LeakyReLU (альфа = 0,2))
# понизить разрешение до 7×7
model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model.add (LeakyReLU (альфа = 0,2))
# классификатор
model.add(Свести())
model.add (плотный (1, активация = ‘сигмоид’))
# скомпилировать модель
model.compile (потеря = ‘binary_crossentropy’, оптимизатор = ‘адам’, метрики = [‘точность’])
модель возврата # определить автономную модель генератора
def определить_генератор (скрытый_дим):
# инициализация веса
инициализация = случайный нормальный (стандартное отклонение = 0,02)
# определить модель
модель = Последовательный()
# основа для изображения 7×7
n_узлов = 128 * 7 * 7
model.add(Dense(n_nodes, kernel_initializer=init, input_dim=latent_dim))
model.add (LeakyReLU (альфа = 0,2))
model.add(Изменить форму((7, 7, 128)))
# повысить разрешение до 14×14
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model. add (LeakyReLU (альфа = 0,2))
# повысить разрешение до 28×28
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init))
model.add (LeakyReLU (альфа = 0,2))
# вывод 28x28x1
model.add (Conv2D (1, (7,7), активация = ‘tanh’, заполнение = ‘то же’, kernel_initializer = init))
модель возврата # определить комбинированную модель генератора и дискриминатора для обновления генератора
def define_gan (генератор, дискриминатор):
# делаем веса в дискриминаторе не обучаемыми
дискриминатор.trainable = Ложь
# соедините их
модель = Последовательный()
# добавляем генератор
model.add(генератор)
# добавляем дискриминатор
model.add(дискриминатор)
# скомпилировать модель
model.compile (потеря = ‘binary_crossentropy’, оптимизатор = ‘адам’)
модель возврата # загрузить изображения mnist
защита load_real_samples():
# загрузить набор данных
(поездX, обучение), (_, _) = load_data()
# расширить до 3D, например. добавить каналы
X = expand_dims (trainX, ось = -1)
# выбрать все примеры для данного класса
selected_ix = обучаемый == 8
Х = Х[выбрано_ix]
# преобразовать из целых чисел в числа с плавающей запятой
X = X. astype(‘float32’)
# шкала от [0,255] до [-1,1]
Х = (Х — 127,5) / 127,5
вернуть Х # выбрать реальные образцы
def generate_real_samples (набор данных, n_samples):
# выбираем случайные экземпляры
ix = randint(0, dataset.shape[0], n_samples)
# выберите изображения
X = набор данных[ix]
# генерируем метки классов
y = единицы ((n_samples, 1))
вернуть х, у # генерировать точки в скрытом пространстве в качестве входных данных для генератора
def generate_latent_points (latent_dim, n_samples):
# генерируем точки в скрытом пространстве
x_input = randn (latent_dim * n_samples)
# преобразовать в пакет входных данных для сети
x_input = x_input.reshape (n_samples, скрытый_дим)
вернуть x_input # использовать генератор для создания n поддельных примеров с метками классов
def generate_fake_samples (генератор, латентный_дим, n_samples):
# генерируем точки в скрытом пространстве
x_input = generate_latent_points (latent_dim, n_samples)
# прогнозировать выходные данные
X = генератор. прогноз(x_input)
# создаем метки классов
у = нули ((n_samples, 1))
вернуть х, у # сгенерировать образцы и сохранить как график и сохранить модель
defsummary_performance(шаг,g_model,latent_dim,n_samples=100):
# подготовить поддельные примеры
X, _ = generate_fake_samples (g_model, hidden_dim, n_samples)
# шкала от [-1,1] до [0,1]
Х = (Х + 1) / 2,0
# сюжетные изображения
для я в диапазоне (10 * 10):
# определить подсюжет
pyplot.subplot(10, 10, 1 + я)
# отключить ось
pyplot.axis(‘выкл’)
# отображать необработанные пиксельные данные
pyplot.imshow(X[i,:,:, 0], cmap=’gray_r’)
# сохранить график в файл
pyplot.savefig(‘results_opt/generated_plot_%03d.png’% (шаг+1))
pyplot.close()
# сохранить модель генератора
g_model.save(‘results_opt/model_%03d.h5′ % (шаг+1)) # создаем линейный график потерь для гана и сохраняем в файл
def plot_history (d1_hist, d2_hist, g_hist, a1_hist, a2_hist):
# сюжетная потеря
pyplot.subplot(2, 1, 1)
pyplot.plot(d1_hist, label=’d-real’)
pyplot. plot(d2_hist, label=’d-fake’)
pyplot.plot (g_hist, метка = ‘ген’)
pyplot.легенда()
# точность дискриминатора графика
pyplot.subplot(2, 1, 2)
pyplot.plot(a1_hist, label=’acc-real’)
pyplot.plot (a2_hist, метка = ‘acc-fake’)
pyplot.легенда()
# сохранить график в файл
pyplot.savefig(‘results_opt/plot_line_plot_loss.png’)
pyplot.close() # обучаем генератор и дискриминатор
def train (g_model, d_model, gan_model, набор данных, hidden_dim, n_epochs = 10, n_batch = 128):
# вычисляем количество батчей за эпоху
bat_per_epo = int(dataset.shape[0]/n_batch)
# рассчитать общее количество итераций на основе партии и эпохи
n_steps = bat_per_epo * n_epochs
# вычислить количество образцов в половине партии
half_batch = int (n_batch / 2)
# готовим списки для хранения статистики каждую итерацию
d1_hist, d2_hist, g_hist, a1_hist, a2_hist = список(), список(), список(), список(), список()
# вручную перечисляем эпохи
для i в диапазоне (n_steps):
# получить случайно выбранные «настоящие» сэмплы
X_real, y_real = generate_real_samples (набор данных, полупакет)
# обновить вес модели дискриминатора
d_loss1, d_acc1 = d_model. train_on_batch(X_real, y_real)
# генерировать «поддельные» примеры
X_fake, y_fake = generate_fake_samples (g_model, hidden_dim, half_batch)
# обновить вес модели дискриминатора
d_loss2, d_acc2 = d_model.train_on_batch(X_fake, y_fake)
# подготовить точки в скрытом пространстве в качестве входных данных для генератора
X_gan = generate_latent_points (latent_dim, n_batch)
# создаем перевернутые метки для поддельных образцов
y_gan = единицы ((n_batch, 1))
# обновить генератор через ошибку дискриминатора
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# суммируем потери в этой партии
print(‘>%d, d1=%.3f, d2=%.3f g=%.3f, a1=%d, a2=%d’ %
(i+1, d_loss1, d_loss2, g_loss, int(100*d_acc1), int(100*d_acc2)))
# запись истории
d1_hist.append(d_loss1)
d2_hist.append(d_loss2)
g_hist.append(g_loss)
a1_hist.append(d_acc1)
a2_hist.append(d_acc2)
# оцениваем производительность модели каждую «эпоху»
если (i+1) % bat_per_epo == 0:
суммарная_производительность (я, g_model, латентный_дим)
plot_history(d1_hist, d2_hist, g_hist, a1_hist, a2_hist) # создаем папку для результатов
makedirs(‘results_opt’, exists_ok=True)
# размер скрытого пространства
скрытый_дим = 50
# создаем дискриминатор
дискриминатор = определить_дискриминатор()
# создаем генератор
генератор = определить_генератор (латентный_тусклый)
# создаем ган
gan_model = define_gan (генератор, дискриминатор)
# загрузить данные изображения
набор данных = load_real_samples()
печать (набор данных. форма)
# модель поезда
поезд (генератор, дискриминатор, модель_гана, набор данных, латентный_дим)
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 9000 2 14 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 25 26 27 28 29 30 28 29 30 0002 3132 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 13121 122 130002 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 151 152 9000 30003 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 7000 183 9000181 1821 183 183 9000 9000 . 0003184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 | # пример обучения нестабильного гана для генерации рукописной цифры от OS Import MakedIrs из Numpy Import Expand_dims от Numpy Import Zeros от Numpy Import One от Numpy.random Importnd Randn из Numpy.random Importint из Keras.datasets.m.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manist.manit. из keras.models импортировать Sequential из keras.layers импортировать Dense из keras.layers импортировать Reshape из keras.layers импортировать Flatten из keras.layers импортировать Conv2D из Keras. из Keras.layers Import Leakyrelu из Keras.initializers Import randomnormal из Matplotlib import # Define Определение DistraTor Model .crimaRINTATOR_FINERINTATOR 2 .CRINERINTATOR 270002.CRINERINTATOR. 28,1)): # инициализация веса init = RandomNormal(stddev=0.02) # определение модели model = Sequential() # понижение разрешения до 14×14 model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init, input_shape=in_shape)) model.add(LeakyReLU(alpha=0.2) )) # понижение разрешения до 7×7 model.add(Conv2D(64, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU (alpha=0.2)) # классификатор model.add(Flatten()) model.add(Dense(1, активация=’сигмоид’)) # компилируемая модель model.compile(loss= ‘binary_crossentropy’, оптимизатор=’адам’, метрики=[‘точность’]) Возврат модели # Определите автономную модель генератора DEF DEFINE_GENERATO # основа для изображения 7×7 n_nodes = 128 * 7 * 7 model. model.add(LeakyReLU(alpha=0.2)) model .add(Изменить форму((7, 7, 128))) # повысить разрешение до 14×14 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add(LeakyReLU(alpha =0.2)) # повысить разрешение до 28×28 model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding=’same’, kernel_initializer=init)) model.add (LeakyReLU(alpha=0.2)) # вывод 28x28x1 model.add(Conv2D(1, (7,7), активация=’tanh’, padding=’same’, kernel_initializer=init)) return model
# определение комбинированной модели генератора и дискриминатора для обновления генератора # соедините их model = Sequential() # добавьте генератор model.add(generator) # добавьте дискриминатор model.add(дискриминатор) # скомпилировать модель model.compile(loss=’binary_crossentropy’, Optimizer=’adam’) модель возврата
# загрузить изображения mnist def load_real_samples() (3 0 dataset 90 90 load_samples(): 30) trainX, trainy), (_, _) = load_data() # расширить до 3d, например добавить каналы X = expand_dims(trainX, axis=-1) # выбрать все примеры для данного класса selected_ix = trainy == 8 X = X[selected_ix] # преобразование из целых чисел в числа с плавающей запятой X = X. # масштабирование от [0,255] до [-1,1] X = (X — 127,5) / 127,5 return X
# выбор реальных образцов def generate_real_samples(dataset, n_samples): # выбор случайных экземпляров ix = randint(0, dataset.shape[0], n_samples) 2 = 0 3 X dataset[ix]# генерировать метки классов y = one((n_samples, 1)) return X, y
# создание точек в скрытом пространстве в качестве входных данных для генератора # преобразование в пакет входных данных для сети x_input = x_input.reshape(n_samples,latent_dim) return x_input
# использование генератора для создания n поддельных примеров с метками классов def Generate_fake_samples (Generator, Latent_DIM, N_SAMPLES): # Сгенерируйте точки в латентном пространстве x_input = Generate_latent_points (latent_dim, n_samples) # Предупреждают выходные. labels y = zeros((n_samples, 1)) return X, y
# генерировать выборки и сохранять их как график и сохранять модель : # подготовить поддельные примеры X, _ = generate_fake_samples(g_model, hidden_dim, n_samples) # масштабировать от [-1,1] до [0,1] X = (X + 1) / 2. # построить изображения для i в диапазоне (10 * 10): # определить подзаговор pyplot.subplot(10, 10, 1 + i) # выключить ось pyplot.axis(‘off’) # рисуем необработанные пиксельные данные pyplot.imshow(X[i, :, :, 0], cmap=’gray_r’) # сохраняем график в файл pyplot.savefig(‘results_opt/generated_plot_%03d.png’ % (step+1)) pyplot.close() # сохранить модель генератора g_model.save(‘results_opt/model_%03d.h5 ‘ % (шаг+1))
# создать линейный график потерь для ган и сохранить в файл def plot_history(d1_hist, d2_hist, g_hist, a1_hist, a2_hist): # график потерь .subplot(2, 1, 1) pyplot.plot(d1_hist, label=’d-real’) pyplot.plot(d2_hist, label=’d-fake’) pyplot.plot(g_hist, label=’gen’) pyplot.legend() # точность дискриминатора графика pyplot.subplot(2, 1, 2) pyplot.plot(a1_hist, label=’ acc-real’) pyplot. pyplot.legend() # сохранить график в файл pyplot.savefig(‘results_opt/plot_line_plot_loss.png’) pyplot.close()
# обучение генератора и дискриминатора def train(g_model, d_model, gan_model, dataset,latent_dim, n_epochs=10, n_batch=128): # вычислить количество пакетов в эпоху bat_per_epo = int(dataset.shape[0] / n_batch) # вычислить общее количество итераций на основе пакета и эпохи n_steps = bat_per_epo * n_epochs 3 # вычислить число выборок в половине партии half_batch = int(n_batch / 2) # подготовка списков для хранения статистики на каждой итерации d1_hist, d2_hist, g_hist, a1_hist, a2_hist = list(), list(), list(), список(), список() # вручную перечислить эпохи для i в диапазоне (n_steps): # получить случайно выбранные «настоящие» выборки X_real, y_real = generate_real_samples(dataset, half_batch) # обновить веса модели дискриминатора d_lossc, d_model. # генерировать фальшивые примеры x_fake, y_fake = generate_fake_samples (g_model, latent_dim, laf_batch) # Обновление модели дискриминатор. ) # подготовить точки в скрытом пространстве в качестве входных данных для генератора генератор через ошибку дискриминатора g_loss = gan_model.train_on_batch(X_gan, y_gan) # суммировать потери на этой партии print(‘>%d, d1=%.3f, d2=%.3f g=%.3f , a1=%d, a2=%d’ % (i+1, d_loss1, d_loss2, g_loss, int(100*d_acc1), int(100*d_acc2))) # История записи D1_HIST.Append (D_LOSS1) D2_HIST.Append (D_LOSS2) G_HIST.Append (G_LOSS) A1_HIST.APPEND (D_ACC1) A2_HIST.APPND (D_ACC1) A2_HIST.ACC2 (D_ACC1) A2 производительность модели каждую «эпоху» if (i+1) % bat_per_epo == 0: summary_performance(i,g_model,latent_dim) plot_history(d1_hist, d2_hist, g_hist, a1_hist, a2_hist) 3 9000 make папка для результатов makedirs(‘results_opt’, exists_ok=True) # размер скрытого пространства latent_dim = 50 # создать дискриминатор compiler = define_distributor() # создать генератор 3 )# создать ган gan_model = define_gan(генератор, дискриминатор) # загрузить данные изображения набор данных = load_real_samples() print(dataset. # модель поезда поезд (генератор, дискриминатор, gan_model, набор данных, латентный_дим) |
Выполнение примера сообщает о потерях и точности для каждого шага во время обучения, как и раньше.
Как мы и ожидали, потери для дискриминатора быстро падают до значения, близкого к нулю, где и остаются, а точность классификации для дискриминатора на реальных и ложных примерах остается на уровне 100%.
>1, d1=0,728, d2=0,902 г=0,763, а1=54, а2=12 >2, d1=0,001, d2=4,509г=0,033, а1=100, а2=0 >3, d1=0,000, d2=0,486 г=0,542, а1=100, а2=76 >4, d1=0,000, d2=0,446 г=0,733, а1=100, а2=82 >5, d1=0,002, d2=0,855 г=0,649, а1=100, а2=46 … >446, d1=0,000, d2=0,000 г=10,410, а1=100, а2=100 >447, d1=0,000, d2=0,000 г=10,414, а1=100, а2=100 >448, d1=0,000, d2=0,000 г=10,419, а1=100, а2=100 >449, d1=0,000, d2=0,000 г=10,424, а1=100, а2=100 >450, d1=0,000, d2=0,000 g=10,427, a1=100, a2=100
1 2 3 4 5 6 7 8 10 11 | >1, d1=0,728, d2=0,902 g=0,763, a1=54, a2=12 >2, d1=0,001, d2=4,509 g=0,033, a1=100, a2=0 >3 , d1=0,000, d2=0,486 g=0,542, a1=100, a2=76 >4, d1=0,000, d2=0,446 g=0,733, a1=100, a2=82 >5, d1=0,002 , d2=0,855 г=0,649, а1=100, а2=46 . >446, d1=0,000, d2=0,000 g=10,410, a1=100, a2=100 >447, d1=0,000, d2=0,000 g=10,414, a1=100, a2= 100 >448, d1=0,000, d2=0,000 g=10,419, a1=100, a2=100 >449, d1=0,000, d2=0,000 g=10,424, a1=100, a2=100 3 > 450, d1=0,000, d2=0,000 г=10,427, а1=100, а2=100 |
Создан график кривых обучения и точности обучения модели с этим единственным изменением.
График показывает, что это изменение приводит к тому, что потери дискриминатора падают до значения, близкого к нулю, и остаются на этом уровне. Важным отличием для этого случая является то, что потери для генератора быстро растут и продолжают расти в течение всего времени обучения.
Линейные графики потерь и точности для генеративно-состязательной сети с ошибкой сходимости из-за агрессивной оптимизации
Мы можем просмотреть свойства ошибки сходимости следующим образом:
- Ожидается, что потери для дискриминатора быстро уменьшатся до значения, близкого к нулю, где они остаются во время обучения.
- Ожидается, что потери для генератора уменьшатся до нуля или будут постоянно уменьшаться во время обучения.
- Ожидается, что генератор будет создавать изображения чрезвычайно низкого качества, которые легко идентифицируются дискриминатором как поддельные.
Дополнительная литература
В этом разделе содержится больше ресурсов по теме, если вы хотите углубиться.
Бумаги
- Генеративно-состязательные сети, 2014.
- Учебное пособие: Генеративные состязательные сети, NIPS, 2016 г.
- Неконтролируемое репрезентативное обучение с помощью глубоких сверточных генеративно-состязательных сетей, 2015 г.
Артикул
- Как обучить ГАН? Советы и рекомендации, как заставить GAN работать
Сводка
В этом руководстве вы узнали, как определить стабильное и нестабильное обучение GAN, просмотрев примеры сгенерированных изображений и графиков показателей, записанных во время обучения.
В частности, вы узнали:
- Как определить стабильный процесс обучения GAN по потерям генератора и дискриминатора с течением времени.
- Как определить сбой режима путем просмотра кривых обучения и сгенерированных изображений.
- Как определить сбой сходимости путем просмотра кривых обучения потерь генератора и дискриминатора с течением времени.
Есть вопросы?
Задавайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Разработайте генеративно-состязательные сети уже сегодня!
Разработка моделей GAN за считанные минуты
… всего несколькими строками кода Python
Узнайте, как в моей новой электронной книге:
Генеративные состязательные сети с Python
В нем содержится учебных пособия для самостоятельного изучения и сквозных проектов на:
DCGAN , условные GAN , перевод изображений , Pix2Pix , CycleGAN
и многое другое. ..
Наконец-то используйте модели GAN в своих проектах технического зрения
Пропустите академиков. Просто Результаты.
Посмотреть, что внутри
О Джейсоне Браунли
Джейсон Браунли, доктор философии, специалист по машинному обучению, который обучает разработчиков тому, как получать результаты с помощью современных методов машинного обучения с помощью практических руководств.
Просмотреть все сообщения Джейсона Браунли →
Как разработать условную GAN (cGAN) с нуля
Обзор моделей генеративно-состязательной сети
Конвергенция, свернутые категории и достоверность конструкции
Анализируя набор данных из 10 политомических заданий с частичным зачетом, я обнаружил, что оценки сложности заданий и их порядок варьировались в зависимости от установленных для оценки пределов сходимости. Порядок важен, потому что он используется в качестве доказательства конструктной валидности инструмента. В моем расследовании расположение предметов было откалибровано дважды. Один раз с пределом сходимости элементов, установленным на 0,01, и еще раз на 0,0005. Размер выборки составил 6520 человек, и распределение способностей людей было примерно нормальным.
Рисунок 1 представляет собой графическое представление различий между местоположениями элементов в двух пределах сходимости. Как и ожидалось, более жесткий (меньший) предел сходимости привел к более рассредоточенным оценкам сложности заданий. Различия в расположении между конвергенцией при 0,01 и сходимостью при 0,0005 удивительно велики. Абсолютные значения различий варьируются от 0,38 до 0,92 логита. Что может быть причиной?
Когда были изучены частоты категорий, было обнаружено, что элементы 6-10 не имели наблюдений в своих крайних высших категориях (см. Таблицу 1). Они были автоматически учтены в моем анализе RUMM2030. Чтобы изучить влияние ненаблюдаемых категорий на расположение предметов, ненаблюдаемые экстремальные категории 5 были объединены с соседними категориями 4. После свертывания этих экстремальных категорий местоположения элементов снова оценивались дважды с пределами сходимости 0,01 и более точно — 0,0001.
На рис. 2 показаны итоговые оценки элементов. По сравнению с оценками на рис. 1 различия в расположении каждого элемента на двух границах сходимости намного меньше. На этот раз абсолютные различия варьировались от 0,10 до 0,42 логита. Хотя в пункты 1–5 не вносились изменения, различия в расположении большинства этих пунктов также уменьшились между двумя пределами сходимости. Разница для пункта 4 оставалась несколько большой, возможно, потому, что пункт 4 имеет только 1 наблюдение в категории 4, его высшей категории, что делает оценку его местоположения сложности менее стабильной.
Как и ожидалось, элементы со свернутыми категориями, элементы 6-10, стали относительно проще, чем в первом, несвернутом анализе. Это связано с тем, что определение сложности задания — это «место на скрытой переменной, в котором верхняя и нижняя категории равновероятны». Свертывание двух высших категорий для каждого элемента сдвинуло объединенную высшую категорию к середине исходной рейтинговой шкалы и, таким образом, сместило положение элемента вниз по скрытой переменной.
В заключение, эти анализы показывают, что пределы конвергенции должны быть установлены достаточно жестко, чтобы быть по существу стабильными. Этот анализ также показывает, что свертывание категорий может привести к заметным изменениям в иерархии сложности заданий. Если категории свернуты и иерархия элементов должна поддерживаться для интерпретации показателей и достоверности конструкции, то может потребоваться опорная привязка (RMT 11:3, стр. 576-7).
Эдвард Ли
| Рисунок 1. Расположение предметов с исходными категориями, включая ненаблюдаемые категории. | Рисунок 2. Расположение элементов с ненаблюдаемыми экстремальными категориями, объединенными с соседними категориями |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Table 1. Original category frequencies of the data Note: # this unobserved category collapsed with adjacent category in the second analysis. |
Конвергенция, свернутые категории и достоверность конструкции. Эдвард Ли … Rasch Measurement Transactions, 2012, 25: 4, 1339
| Публикации Раша | ||||
|---|---|---|---|---|
| Транзакции измерения Раша (бесплатно, онлайн) | Исследовательские работы по измерению Раша (бесплатно, онлайн) | Вероятностные модели для некоторых тестов интеллекта и достижений, Георг Раш | Применение модели Раша 3-й. Изд., Бонд и Фокс | Лучший дизайн теста, Wright & Stone |
| Анализ рейтинговой шкалы, Wright & Masters | Введение в измерение Раша, Э. Смит и Р. Смит | Введение в многогранное измерение Раша, Томас Экес | Инвариантное измерение: использование моделей Раша в социальных, поведенческих и медицинских науках, Джордж Энгельхард-младший | Статистический анализ для языковых тестеров, Rita Green |
| Модели Раша: основы, последние разработки и приложения, Fischer & Molenaar | Журнал прикладных измерений | Модели Rasch для измерения, David Andrich | Строительные меры, Марк Уилсон | Анализ Раша в гуманитарных науках, Boone, Stave, Yale |
| на испанском: | Analisis de Rasch para todos, Агустин Тристан | Mediciones, Posicionamientos y Diagnósticos Competitivos, Juan Ramón Oreja Rodríguez | ||
| rasch.org , введите свой адрес электронной почты здесь: Я хочу Подписаться : & нажмите ниже Я хочу Отписаться : & нажмите ниже Пожалуйста, настройте СПАМ-фильтр на прием писем от Rasch.org |
www.rasch.org приветствует ваши комментарии: |
| Форум | Форум по измерению Раша для обсуждения любой темы, связанной с Рашем |
Перейти к началу страницы
Перейти к указателю всех операций измерения Раша
Члены AERA: Присоединяйтесь к группе Rasch Measurement SIG и получите печатную версию RMT
Некоторые старые выпуски RMT доступны в виде связанных томов
Подпишитесь на журнал прикладных измерений
Перейти на домашнюю страницу Института объективных измерений. Измерение Раша SIG (AERA) благодарит Институт объективных измерений за предложение опубликовать транзакций измерения Раша на веб-сайте Института, www.rasch.org.
| Предстоящие события, связанные с Рашем | |
|---|---|
| 7 октября — 4 ноября 2022 г., пт.-пт. | Онлайн-семинар: Практическое измерение Раша — основные темы (Э. Смит, Winsteps), www.statistics.com |
| 2–30 ноября 2022 г., ср.–ср. | Онлайн-курс: промежуточный/продвинутый анализ Раша (М. Хортон, RUMM2030), Medicinehealth.leeds.ac.uk |
| 1-3 декабря 2022 г., чт.-сб. | Очная конференция: Симпозиум по объективным измерениям Тихоокеанского региона (PROMS) 2022 proms.promsociety.org |
| 25 января — 8 марта 2023 г., ср..-ср. | Онлайн-курс: Вводный анализ Раша (М. Хортон, RUMM2030), Medicinehealth.leeds.ac.uk |
| 23 июня — 21 июля 2023 г., пт. -пт. | Онлайн-семинар: Практическое измерение Раша — дополнительные темы (Э. Смит, Winsteps), www.statistics.com |
| 11 августа — 8 сентября 2023 г., пт. | Онлайн-семинар: Многогранное измерение Раша (Э. Смит, Facets), www.statistics.com |
URL этой страницы: www.rasch.org/rmt/rmt254a.htm
Веб-сайт: www.rasch.org/rmt/contents.htm
Мониторинг хода обучения GAN и выявление распространенных режимов отказа — MATLAB & Simulink
Основное содержание
Мониторинг прогресса обучения GAN и выявление общих режимов отказа
Обучение GAN может быть сложной задачей. Это связано с тем, что генератор и
дискриминаторные сети конкурируют друг с другом во время обучения. На самом деле, если один
сеть обучается слишком быстро, тогда другая сеть может не обучиться. Это часто может привести
в сети невозможно сойтись. Для диагностики проблем и мониторинга по шкале от 0
до 1, насколько хорошо генератор и дискриминатор достигают своих целей, которые вы можете построить
их баллы. Для примера, показывающего, как обучить GAN и построить генератор и
баллы дискриминатора, см. Обучение генеративно-состязательной сети (GAN). 9Real содержит выходные вероятности дискриминатора для реальных изображений и
числа реальных и сгенерированных изображений, переданных дискриминатору, равны.
В идеальном случае обе оценки должны быть равны 0,5. Это потому, что дискриминатор не может сказать разница между реальными и поддельными изображениями. Однако на практике этот сценарий не единственный случай, когда вы можете добиться успешной ГАН.
Для наблюдения за ходом обучения вы можете визуально просматривать изображения с течением времени и проверять
если они улучшаются. Если изображения не улучшаются, вы можете использовать график оценки для
помочь вам диагностировать некоторые проблемы. В некоторых случаях график счета может сказать вам, что нет
продолжать тренировку, и вы должны остановиться, потому что возник режим отказа, который
тренировка не может оправиться от. В следующих разделах рассказывается, что искать в партитуре.
на графике и в сгенерированных изображениях для диагностики некоторых распространенных режимов отказа (сбой конвергенции
и свертывание режима) и предлагает возможные действия, которые можно предпринять для улучшения
подготовка.
Ошибка сходимости
Ошибка сходимости происходит, когда генератор и дискриминатор не достигают баланс во время тренировки.
Дискриминатор доминирует
Этот сценарий происходит, когда оценка генератора достигает нуля или почти нуля, а оценка дискриминатора достигает единицы или близка к единице.
На этом графике показан пример дискриминатора, подавляющего генератор. Уведомление
что оценка генератора приближается к нулю и не восстанавливается. В этом случае
дискриминатор правильно классифицирует большинство изображений. В свою очередь, генератор не может
производить любые изображения, которые обманывают дискриминатор и, таким образом, не в состоянии учиться.
Если оценка не восстанавливается после этих значений в течение многих итераций, то лучше прекратить обучение. Если это произойдет, попробуйте сбалансировать производительность генератор и дискриминатор по:
Нарушение работы дискриминатора путем случайного присвоения ложных меток реальным изображения (одностороннее переворачивание этикетки)
Ухудшение работы дискриминатора путем добавления выпадающих слоев
Улучшение способности генератора создавать больше функций путем увеличение количества фильтров в его сверточных слоях
Ухудшение работы дискриминатора за счет уменьшения количества фильтров
Пример, показывающий, как переворачивать метки реальных изображений, см. в разделе Обучение генеративно-состязательной сети (GAN).
Генератор доминирует
Этот сценарий происходит, когда счет генератора достигает единицы или почти единицы.
На этом графике показан пример того, как генератор подавляет дискриминатор. Уведомление что оценка генератора идет к единице для многих итераций. В этом случае генератор учится обманывать дискриминатор почти всегда. Когда это происходит очень в начале процесса обучения генератор, скорее всего, выучит очень простой представление признаков, которое легко обманывает дискриминатор. Это означает, что сгенерированные изображения могут быть очень плохими, несмотря на высокие баллы. Обратите внимание, что в этом Например, оценка дискриминатора не очень близка к нулю, потому что она все еще в состоянии правильно классифицировать некоторые реальные изображения.
Если оценка не восстанавливается после этих значений в течение многих итераций, то
лучше прекратить обучение. Если это произойдет, попробуйте сбалансировать производительность
генератор и дискриминатор по:
Улучшение способности дискриминатора изучать больше функций путем увеличение количества фильтров
Ухудшение работы генератора путем добавления отсеивающих слоев
Ухудшение работы генератора за счет уменьшения количества фильтров
Коллапс режима
Коллапс режима — это когда GAN создает небольшое количество изображений с большим количеством дубликатов. (режимы). Это происходит, когда генератор не может изучить расширенную функцию. представление, потому что оно учится связывать похожие результаты с несколькими разными входы. Чтобы проверить свертывание режима, проверьте сгенерированные изображения. если мало разнообразие в выводе и некоторые из них практически идентичны, то скорее всего режим крах.
На этом графике показан пример коллапса режима. Обратите внимание, что сгенерированные изображения строятся
содержит множество практически идентичных изображений, несмотря на то, что входные данные генератора были
разные и случайные.
Если вы наблюдаете подобное, то попробуйте увеличить способность генератора создавать более разнообразные результаты:
Увеличение размерности входных данных в генератор
Увеличение количества фильтров генератора, чтобы он мог генерировать широкий выбор функций
Нарушение работы дискриминатора путем случайного присвоения ложных меток реальным изображениям (одностороннее переключение меток)
Пример, показывающий, как переворачивать метки реальных изображений, см. в разделе Обучение генеративно-состязательной сети (GAN).
См. также
dlnetwork | вперед | предсказать | дальрей | dlградиент | dlfeval | Адамобновление
Связанные темы
- Обучение генеративно-состязательной сети (GAN)
- Обучение условно генеративно-состязательной сети (CGAN)
- Определение пользовательских циклов обучения, функций потерь и сетей
- Обучение сети с использованием пользовательского цикла обучения Пользовательский Указать параметры обучения в Цикл обучения
- Список слоев глубокого обучения
- Советы и рекомендации по глубокому обучению
- Фон автоматического дифференцирования
Вы щелкнули ссылку, соответствующую этой команде MATLAB:
Запустите команду, введя ее в командном окне MATLAB.